
This article breaks down the process I’ve used to train and fine-tune multimodal language models. It’s allowed me to create custom and accurate AI solutions without spending much time or money.
It’s not a technical piece but to implement the steps you will need some developer know-how. If that doesn’t sound like you, that’s okay. You can always read it and pass on the ideas to your engineering team for execution.
I’ve also listed out real business use cases that you can fine-tune a multimodal language model around.
![Scientists in lab coats examine a large screen displaying "How to Train and Fine Tune a Multimodal Language Model [+ Use Cases]" amid servers.](https://hatchworks.com/wp-content/uploads/2024/09/How-to-Train-and-Fine-Tune-a-Multimodal-LLM-Asset-57-1024x538.png)
Who am I? Great question.
👋 I’m Oscar Romero, Senior Data and ML Engineer at HatchWorks AI. I’m obsessed with all things AI and machine learning. So much so that I’m heading back to school to ensure I keep up with the pace of AI development. At work, I apply my learnings to client projects to accelerate development and reduce processing time by 20%.
Short on time? Get the highlights with these three key takeaways:
- Fine-tuning a multimodal language model is faster and more cost-effective than training from scratch. And it lets you tailor AI to your specific business needs.
- There’s more than one way to fine-tune your language model. I like to use the transfer learning approach because it reduces computational time and costs.
- Multimodal language models have diverse real-world applications, from analyzing customer sentiment in text and voice to enabling visual search in e-commerce and assisting with medical diagnostics. Which one you use it for is up to you and your business needs.
Watch the full webinar:
This article is based on my 1-hour long webinar where I demonstrate step-by-step how I train one multimodal Contrastive Language Model (CLM) and fine-tune another.
The webinar offers a more in-depth look at each step.
📽️ Watch it here.
Looking Under AIs Hood: Neural Network Architectures
Before we even think about training a language model to be multimodal let’s get to grips with some basics.
After all, if you were going to tinker around with a car, the first thing you’d do is pop the hood to see what you’re working with.
When you look under an language model’s hood you’ll find, not an engine, but a neural network architecture.
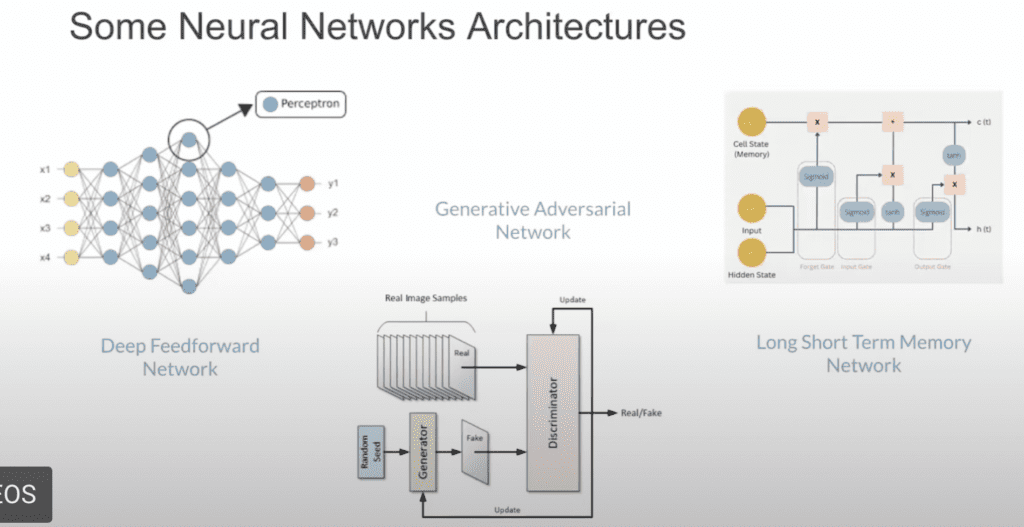
Each neural network architecture type is designed to excel at different tasks. Just like how a diesel engine is better for endurance while a gasoline engine may be more versatile.
For instance, Convolutional Neural Networks (CNNs) are great at image processing, while Recurrent Neural Networks (RNNs) and Transformers are well-suited for sequential data like text.
These architectures form the basis of an language model’s capabilities. Combining architectures is what makes a language model multimodal.
📚You may also like: Large Language Models: Capabilities, Advancements, and Limitations [2024] and How AI as an Operating System is Shaping Our Digital Future
What is a Multimodal Language Model?
A multi-modal language model can process and generate data across different modalities—like text, images, as well as other formats (audio, video, etc.).
It’s trained to understand and generate outputs that are contextually appropriate for the given input modalities.
Here are some key components of a multimodal language model:
- Text Encoder: Converts text inputs into a format (usually embeddings) that the model can process.
- Vision Encoder: Converts images into embeddings.
Cross-Attention Mechanism: Integrates information across modalities. - Decoder: Generates outputs based on processed multimodal inputs.
- Fusion Layer: Combines information from different modalities into a unified representation.
- Task-Specific Heads: Specialized layers for different tasks (e.g., classification, generation, question-answering).
And here are some examples of multimodal language models you probably use already:
- ChatGPT with DALL-E Integration: While ChatGPT itself is primarily text-based, its integration with DALL-E allows users to generate and edit images based on text descriptions, making it a multimodal system.
- Google Lens: This app can identify objects, landmarks, and text in images, and provide relevant information or translations, combining vision and language processing.
- Siri, Alexa, and Google Assistant: These virtual assistants process both voice and text inputs, and can respond with audio or text, making them multimodal systems.
The capabilities and complexities of multimodal language models are getting impressive fast. Take GPT 4o and what it’s capable of:
How to Train a Multimodal Language Model
Training language models is resource-intensive and time-consuming. Usually, I wouldn’t recommend it—not when so many companies like Mistral and Open AI have done the groundwork for us.
But let’s say we need an language model to process both text and images and we want to build it ourselves. Here are the steps I would follow to make that possible.
1. Setting Up the Model Architecture
For this example, I’m using a convolutional neural network. Remember, it will function as the engine of our Contrastive Language Model (CLM).
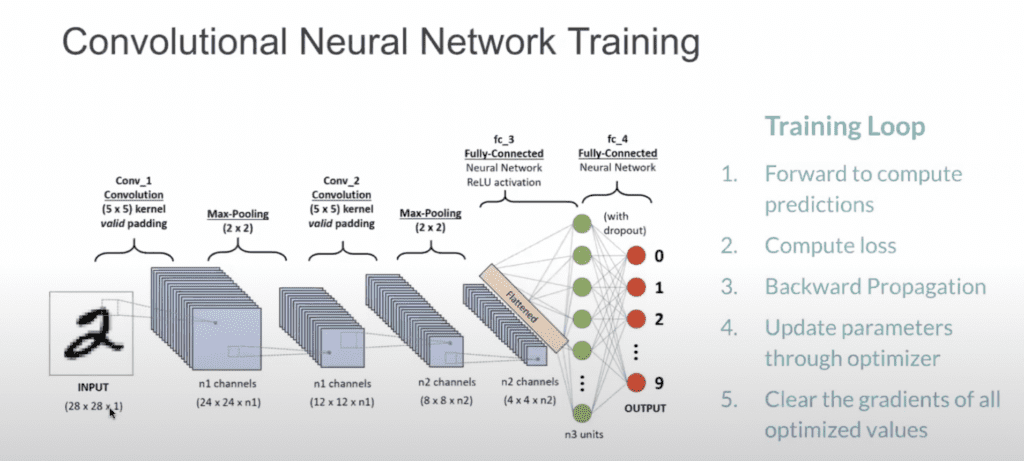
The core of your multimodal language model will consist of two main components:
- Text Encoder: This part processes text input. It typically uses an embedding layer followed by transformer layers or recurrent neural networks (RNNs).
- Image Encoder: This is where CNN comes in.
A typical CNN for image processing includes:
- Convolutional layers: These apply filters to extract features from the image.
- Pooling layers: These reduce spatial dimensions, focusing on the most important features.
- Flatten layer: This converts the 2D output from convolutional layers into a 1D vector.
- Dense (fully connected) layers: These learn complex patterns from the flattened features.
The outputs from both encoders are then combined in a fusion layer, which can be as simple as concatenation or as complex as attention mechanisms.
2. Data Preprocessing
Before training, you need to prepare your data. As we’re creating a model that can process both images and text, those are the datasets we’ll need.
- Text Data: Tokenize the text and convert it into integer values that represent words. Use torchtext or similar libraries for this. Ensure that your text data is padded or truncated to a fixed length.
- Image Data: Convert images into pixel values (typically in the range 0 to 1). Since we’re dealing with grayscale images, each pixel’s intensity ranges from 0 (black) to 1 (white). PyTorch’s torchvision library can handle this.
Language models can’t look at an image and understand it in the same way we do. So we have to assign it a value and then assign pixels to the image so that the model can ‘read’ the picture by determining the value of the pixels.
You can see below that we’re showing our Contranstive Language-Image Model 10 numbers (0-9).


3. Training the Model
With your data ready, it’s time to load it into your language model.
There are a few concepts you need to understand here:
- Batching: Load your data in batches (e.g., 28 images at a time) to efficiently utilize GPU resources.
- Training Loop: Feed the batches to the model, compute the loss, and backpropagate the error to update the model weights.
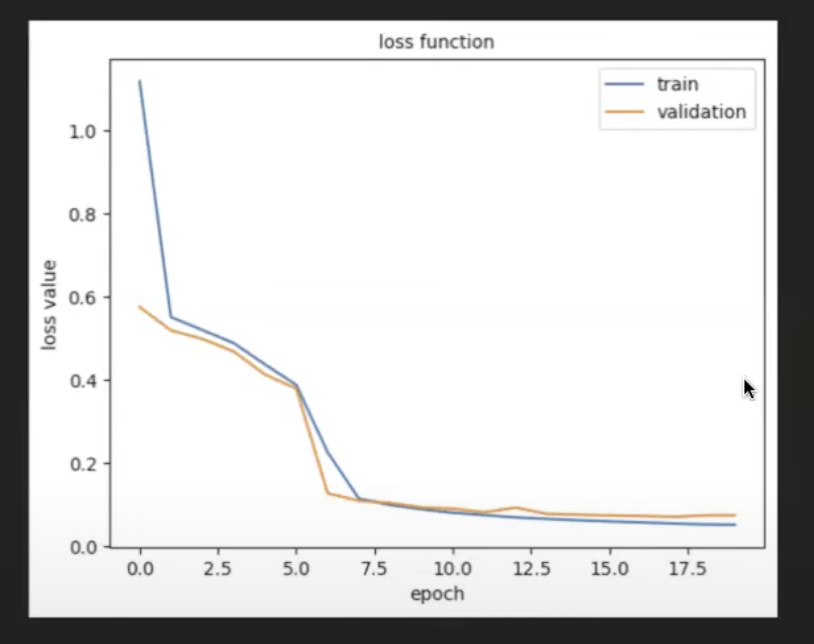
- Epochs: The number of epochs (iterations over the entire dataset) is determined through experimentation. Monitor the loss rate, and stop training if the loss starts increasing, indicating overfitting.
How do you know how many epochs are enough? Experimentation.
If you monitor the loss function and it goes down, you want to keep doing epochs. But if it starts to go back up, you have trained it too much and it’s having an adverse effect on the output.
How to Fine-Tune a Multimodal Language Model
Fine-tuning is something I would recommend. Where training is laborious and expensive, fine-tuning is fast and affordable.
Plus, it can take a run-of-the-mill lanaguage model and tailor it to your exact needs.
Here are the steps I took as I fine-tuned a pre-trained Contranstive Language-Audio Model to recognize and categorize sentiment in music.
1. Choose from these Pre-Trained models
Fine-tuning generally starts with a pre-trained model, which has already learned a good representation of multimodal data. You load this model and then train it further on your specific dataset.
You can find pre-trained models on the Hugging Face platform. This saves you from training something from scratch.
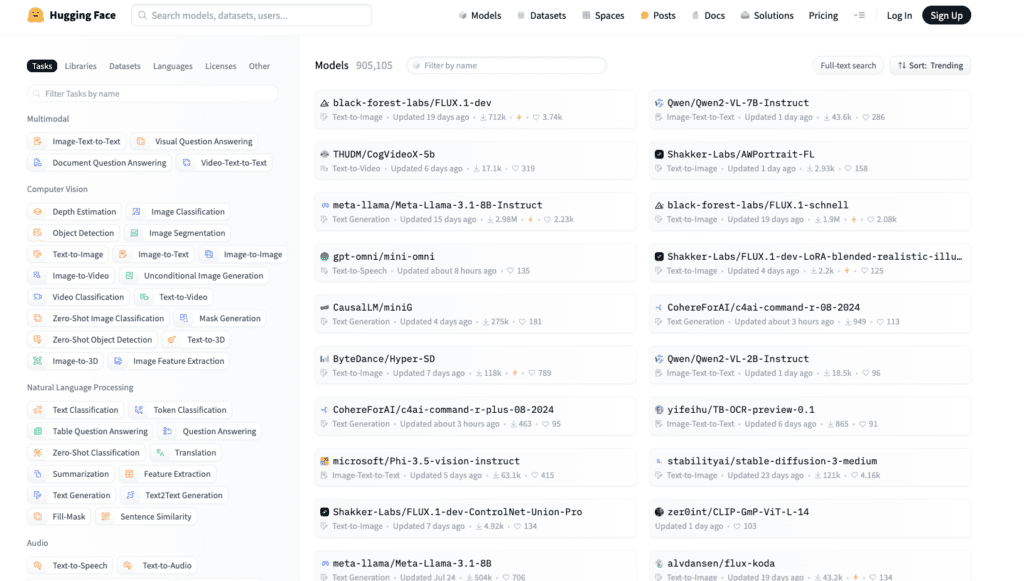
💡Pro tip: Filter through Hugging Face’s repository by multimodal type, characteristics, and capabilities to find the exact one you need quickly. All you have to do is look to the left of the screen and click through the different criteria.
We’re using CLUB (Contrastive Language-Understanding-Based) as our base model. It can process audio and text.
When you choose yours, you need to think about what use case you’re fine-tuning for. I’ve included some examples of those at the end of this article.
2. Choose Your Fine-Tuning Approach
In our example, we’re using transfer learning as our fine-tuning approach.
This involves taking CLUB, which is pre-trained on general multimodal tasks, and adapting it for a new task—in our case, music sentiment analysis.
Other approaches include Low-Rank Adaptation (LoRA). It’s a popular method, particularly efficient for fine-tuning large language models with fewer parameters.
You can learn more about how to apply LoRA in our article and webinar: How to Use Small Language Models for Niche Needs in 2024.
3. Test the Capabilities of Your Model as Is
Before fine-tuning, it’s essential to understand the base capabilities of the pre-trained model.
For example, if the model is pre-trained on general multimodal tasks, it might be capable of generating convincing audio responses like a dog barking when prompted with related text.
This step helps establish a baseline so you can see how the model’s performance changes after fine-tuning.
4. Inputting Your New Dataset
For our specific fine-tuning task, we’re going to train the model to classify the sentiment of songs—something the pre-trained model isn’t originally designed for.
We need a dataset of songs labeled by sentiment categories such as ‘happy,’ ‘sad,’ ‘suspense,’ and ‘epic’.
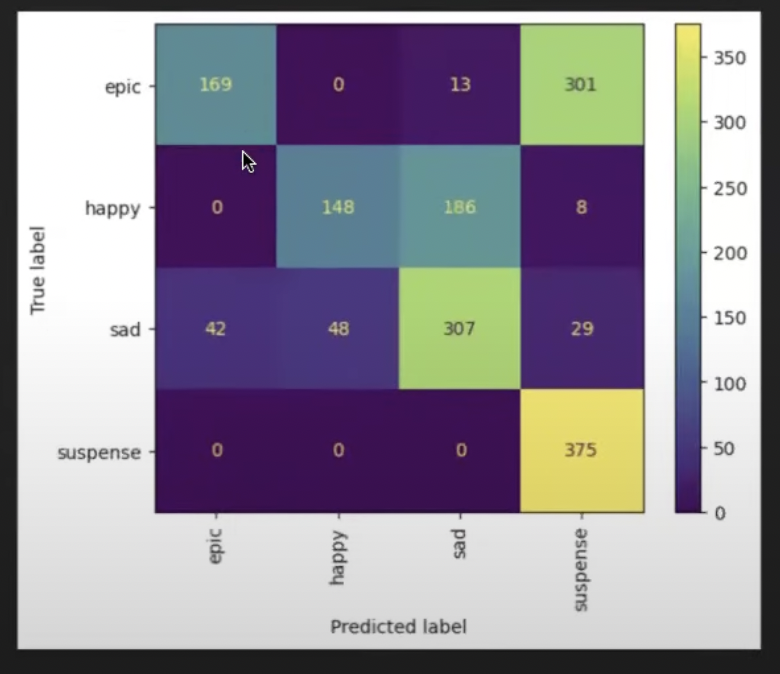
In this case, we have 1,500 audio files categorized into those categories which we’ll load into the model.
5. Building the Fine-Tuning Architecture
You’re next going to build a simple neural network on top of the pre-trained CLUB model.
In the image, the architecture on the left is the existing CLAP architecture. The one on the right is what we need to build on top of it.
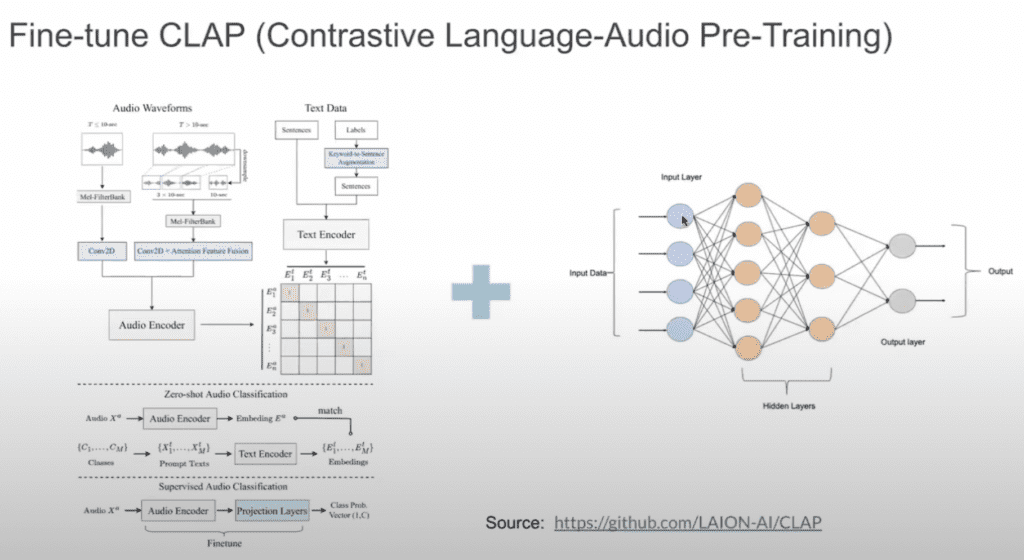
Here’s how to set up your fine-tuning process:
- Load the Pre-trained Model: Import CLUB and freeze its layers to prevent updates during the initial fine-tuning phases. This focuses the training on the new layers you’ll add.
- Add New Layers: Construct a simple neural network on top of CLUB. This could be a few dense layers culminating in an output layer matching your sentiment categories.
- Set Up Optimizer and Loss Function: Choose an optimizer with a low learning rate to avoid drastically altering the pre-trained weights. Your loss function should match your task (e.g., categorical cross-entropy for multi-class sentiment classification).
6. Fine-Tuning the Model
Now it’s time to actually fine-tune your model:
Feed batches of audio data and their sentiment labels through the model.
After fine-tuning, test the model using a validation set or new audio inputs. For example, try classifying a “Game of Thrones” soundtrack to see if it’s correctly labeled as “Epic” rather than “Sad”.
Keep testing until you feel confident the model is producing reliable and accurate outputs.
📚You may also like: AI Inference vs Training vs Fine Tuning | What’s the Difference?
7. Iterating and Improving the Model
Still struggling with the quality of your output? Consider the following:
- Adjust Network Complexity: If performance is poor, your added classifier might be too simple. Try building a more complex architecture, perhaps adding more layers or using techniques like dropout to prevent overfitting.
- Experiment with Hyperparameters: Adjust learning rates, batch sizes, or the number of epochs to optimize performance.
- Gradual Unfreezing: Instead of fine-tuning all layers at once, try progressively unfreezing and fine-tuning layers of the base model.
- Data Augmentation: If your dataset is small, consider augmenting it with techniques like pitch shifting or time stretching for audio data.
The key is to iterate without retraining the entire model from scratch because that would be too time-consuming and resource-intensive.
Next Steps: Think About Use Cases Where You Need a Multimodal Language Model
There’s no use in training or fine-tuning a multimodal language model unless it improves the way you and your business operates. So before you set your team to the task, think about how best a multimodal language model can be used.
Here are some ideas I’ve come up with:
1. Customer Support and Sentiment Analysis
In customer service, understanding the sentiment of customer interactions can enhance the quality of support. A multimodal language model can analyze both the textual content of customer emails or chat messages and the tone of voice in phone calls or voice notes.
This is similar to what I did in my own example with music sentiment. Imagine if you had a system that could organize customer support emails and calls by sentiment. Then you could hand off those cases to agents who are best suited to the job.
2. E-Commerce and Visual Search
Multimodal language models can be used in e-commerce to enable visual search capabilities. Customers can upload an image of a product they are interested in, and the system can match it with similar products in the catalog, providing both visual and textual information.
3. Content Moderation and Compliance
Social media platforms or online communities need to ensure that content adheres to community guidelines. A multimodal language model can analyze both the textual and visual content of posts to detect inappropriate or harmful material.
4. Healthcare and Diagnostics
In healthcare, multimodal language models can be used to assist in diagnostics by analyzing medical images (like X-rays or MRIs) in conjunction with patient notes or symptoms described in text.
Ready to Bring Your AI Use Case to Life?
While you can use this article and its accompanying webinar to guide your own training and fine-tuning of a multimodal language model, don’t feel like you have to go at it alone. At HatchWorks AI we offer services to support you in your implementation of AI and we have a do it for you service. Check out our offerings below:- A AI Roadmap and ROI Workshop that equips you with the knowledge to understand and apply AI to real-world use cases in your business.
- A AI Solution Accelerator program that takes you from idea to prototype to product faster. This approach provides a low-risk, high-value pathway for companies to validate and test AI technology on a small scale before committing to full production.
- Our RAG Accelerator will help you integrate any AI model and data source into your workflow. We tailor the service to you by safely and securely using your data to keep your AI up to date and relevant without spending time or money training (or fine-tuning) the model.
- AI-Powered Software Development—why build for yourself when we can do it for you in half the time?
Don’t Forget to Watch the Full Webinar
In the webinar, we cover more nuance and answer FAQs related to training and fine-tuning a multimodal model.
Check it out here.

Train and Fine Tune Multimodal LLM FAQ
What is a multimodal language model, and why should I consider training and fine-tuning one?
A multimodal language model is an AI model capable of processing and generating data across different modalities, such as text, images, audio, and video. Training and fine-tuning such a model allows you to tailor AI solutions to your specific business needs, enhancing its ability to handle both textual and visual features simultaneously. This leads to a more comprehensive understanding of your data and improves the model’s performance in tasks like computer vision and visual question answering.
How can I fine-tune an existing base model using my proprietary data?
You can start with an existing model like the CLUB (Contrastive Language-Understanding-Based) model, as mentioned in the article. By applying transfer learning and performing supervised fine-tuning on this base model with your proprietary data, you adjust the model weights to better suit your specific use case. This process leverages your unique training data to develop a fine-tuned model that excels in your targeted applications.
What are the key steps in training a multimodal language model from scratch?
Training a multimodal language model involves several key steps:
Setting Up the Model Architecture: Combining different neural network architectures (like CNNs for images and transformers for text) to handle multiple modalities.
Data Preprocessing: Preparing both text and image data by tokenizing text and converting images into pixel values.
Training the Model: Using concepts like batch size, training loops, and epochs to efficiently train the model while monitoring the loss function to prevent overfitting.
These steps help in building a model that can process both images and text, enabling it to perform tasks involving visual features and language understanding.
Why is fine-tuning preferred over training a model from scratch?
Fine-tuning is preferred because it is faster and more cost-effective than training a model from scratch. By starting with a pre-trained base model, you can adapt it to your specific tasks using a smaller amount of training data. This approach reduces computational time and costs while still achieving higher performance tailored to your needs. It allows you to leverage existing model weights and focus on improving the model for your specific use case.
What are some real-world use cases for fine-tuned multimodal language models?
Fine-tuned multimodal language models have diverse applications, such as:
Customer Support and Sentiment Analysis: Analyzing both text and voice data to understand customer sentiment.
E-Commerce and Visual Search: Enabling visual search capabilities by processing both images and text descriptions.
Content Moderation and Compliance: Analyzing visual and textual content to detect inappropriate material.
Healthcare and Diagnostics: Assisting in diagnostics by analyzing medical images along with patient notes.
These use cases demonstrate how fine-tuned multimodal models can provide a more comprehensive understanding and improve the quality of AI solutions in various industries.
Talk to Our AI Experts
AI is transforming every business.
Make sure it transforms yours for the better.



