
The process of integrating a Large Language Model (LLM) into your business is overwhelming, especially if this is your first time attempting it.
While the potential benefits (boosted efficiency, sharper insights, and a competitive edge that could redefine your market position) are great, getting it wrong could mean wasted resources, missed opportunities, or worse putting your proprietary data at risk.

We wrote this 6-step guide to put you on the path to seamless implementation. It strikes a balance between technical know-how and strategic thinking—everything you care about as a CTO.
Ready to bring AI to the heart of your product?
With our expertise in AI-Native product development, we handle every step—from strategy and PoC validation to deployment and optimization.
Let us build intelligent, adaptive, and impactful user experiences while you focus on driving your business forward.
Implementation can’t begin until you know how you want to use an LLM in your business.
So, we’ll start there—think of it as a precursory step. Your use case will determine the value you extract from this bit of tech.
Start by examining your current operations:
- Where are the bottlenecks?
- What tasks eat up too much time?
- Which processes could benefit from faster access to proprietary data?
Your answers will point you toward potential LLM applications.
Need some inspiration?
- Morgan Stanley equipped their wealth advisors with an OpenAI-powered assistant that helped them give better financial advice to clients.
- In the healthcare sector, Apollo 24|7 is using Google’s MedPaLM with RAG to pull up relevant medical info in a pinch.
- And Cox2M (a HatchWorks AI client) has used RAG to give their customers real-time insights into their fleets.

Challenge: Cox2M aimed to create a Generative AI trip analysis assistant for their Kayo fleet management customers, providing real-time, accurate natural language responses about complex fleet data.
Solution: HatchWorks AI developed the Kayo AI Assistant by implementing our RAG Accelerator enabling customers to get real time insights about their fleet through natural language.
Results: The scalable, cost-effective system was delivered on time, enabling easy implementation and scaling across cloud platforms, enhancing fleet management.
These examples show how LLMs can enhance decision-making, automate information retrieval, and improve customer experience.
Your use case might resemble one of these examples or be entirely unique. If you’re unsure where to start, we’re here to help. Get in touch with us here and we’ll chat through the possibilities specific to your business.
📚RAG resources you’ll love: RAG for Healthcare, RAG for Financial Services
6 Steps to Integrating an LLM into Your Business
Now that you’ve pinpointed your use case, you can begin implementation of the LLM into your business. These 6 steps can be a little technical, but they’re relatively straight forward.Expert tip:
If you find you don’t have the in-house support to apply them, HatchWorks AI does and we’re happy to lend our expertise. You can upskill using our AI resources or engage us in the way that best meets your needs (staff augmentation, dedicated agile teams, or outcome based projects)
Check those engagement options out here.
Step 1: Choosing the Right LLM
Good news—you don’t need to build and train an LLM from scratch. Instead, you can use one that already exists (and there’s a wide range available). From GPT models to BERT variants, each has its own strengths and is built to specific use cases.
That’s why your choice matters so much. If you were hanging a picture on your wall and you had a hammer and wrench in front of you, which would you choose? While both are useful, one is the right tool for this particular job. It’s the same with different LLMs
You want to find one that’s been trained to efficiently execute the tasks you have in mind.
The first decision to make is simple: use a managed service or host your own.
Managed services make it very easy to get up to speed, interacting with an API. Companies including OpenAI and Anthropic expose their LLMs through accessible APIs. Hyperscalers also offer LLM marketplaces, such as GCP’s ModelGarden, and managed LLM services, such as Amazon Q.
But managed services aren’t always the best option –
- commercially, the unit economics of consuming hosted models may not be feasible;
- functionally, the performance of a hosted model may fall short for your specific use-case;
- security-wise, the transfer of code or data to a third-party service can be prohibitive in highly regulated or competitive industries.
If you decide you are looking to host your own, your first stop should be the Hugging Face Repository. That’s where our HatchWorks developers always go.
It’s a treasure trove of LLMs, complete with filters to help you narrow down your search based on task, language, and model size among other factors.
As you flip through the options, consider your use case.
- What specific problem are you aiming to solve with an LLM in your industry?
- Are you after general knowledge or domain-specific expertise?
- Do you need multilingual or multimodal capabilities?
- How about the model’s size—can your infrastructure handle a lot, or do you need something leaner?
- What are the compliance and regulatory considerations for deploying an LLM in your sector?
Then choose the one that meets your needs best. Here are some we recommend based on common use cases we see:
| Industry | Use Case | Recommendation |
|---|---|---|
|
Enhancing customer support with intelligent chatbots.
|
Llama 3.1 for its advanced language understanding and generation capabilities.
|
|
|
Assisting developers with code generation and debugging.
|
Codestral Mamba: A cutting-edge LLM tailored for complex technical tasks and code generation.
|
|
|
Summarizing clinical notes and patient interactions.
|
ClinicalBERT for its focus on medical terminology and records.
|
|
|
Automating financial report generation and risk assessment.
|
FinBERT tailored for financial data analysis.
|
|
|
Crafting personalized marketing campaigns.
|
Llama 3.1 to generate compelling and customized content.
|
📚 For a comprehensive look at Codestral Mamba—including its features, performance metrics, and how it stacks up against other models—be sure to read our article: A Complete Guide to Codestral Mamba: Features, Performance, and Comparison
You may be tempted to go with a larger model that has vast capabilities. But that’s not always your best option.
Here’s a quick breakdown of how larger and smaller models stack up against each other:
| Larger Models | Smaller Models | |
|---|---|---|
|
Performance
|
Generally higher accuracy and capability on complex tasks
|
May have lower accuracy on complex tasks, but often sufficient for simpler use cases
|
|
Computational Resources
|
Require significant GPU/TPU power and memory
|
Can run on less powerful hardware, including edge devices
|
|
Inference Speed
|
Slower due to more parameters to process
|
Faster, allowing for real-time applications
|
|
Cost
|
Higher operational costs due to greater computational needs
|
Lower operational costs, more cost-effective for scaling
|
|
Flexibility
|
More adaptable to a wide range of tasks without fine-tuning
|
May require fine-tuning for specific tasks, but can be more easily customized
|
|
Deployment
|
Often limited to cloud or powerful on-premises servers
|
Can be deployed on a wider range of devices, including mobile and IoT
|
|
Privacy & Data Handling
|
May require sending data to external servers if cloud-based
|
Can often be run locally, enhancing data privacy and reducing latency
|

Want to learn how to use small language models for industry-specific use cases?
Check out this webinar where we show you how to do just that:
A Quick Note on Fine-Tuning: Your Solution to Customizing a Pre-Built LLM
Sometimes a pre-built LLM isn’t optimized enough for your use case. But building an LLM from scratch is costly and time-consuming. The solution? Fine-tuning one.
Here’s why fine-tuning works so well:
- It’s cost-effective: Fine-tuning requires less data and compute power than training from scratch, saving you time and money.
- It gives your AI a performance boost: It can significantly improve performance on your specific tasks, often outperforming larger, general-purpose models.
- It can be customized: You can adapt the model to your industry jargon, company voice, or specific data formats.
- It leaves a smaller footprint: Fine-tuned models are often smaller and faster than their base models, making deployment easier.
- You can continuously improve it: As your data evolves, you can periodically re-tune your model to keep it sharp. This is especially true if you are using a RAG architecture.
Learn more about fine-tuning LLMs by watching our webinar: Create and Fine Tune Your Own Multimodal Model
Step 2: Accessing the LLM via API
Once you’ve selected and configured your LLM, you can communicate with it. All LLMs have an API that governs how you interact with it. Whether you are consuming a managed service or running a self-hosted model either locally or on the cloud, there will be a specific interface you use to access the LLM. These APIs let your systems send requests to the LLM, process inputs (like text), and receive outputs (like generated responses or predictions) with minimal effort. To begin, you’ll need to:- Obtain an API Key: Depending on whether you self-host your model or use a managed service, you’ll want a secure way to access it. API Keys are one way to do that.Register for an account on your LLM provider’s platform. Navigate to the developer dashboard to locate your unique API key. This key is essential for authentication and should be kept secure.
- Review API Documentation: Familiarize yourself with the provider’s API documentation. Key elements to understand whether working with a managed platform or a self-hosted one include:
- Endpoints: The specific URLs for different API functions
- Request formats: How to structure your API calls
- Response structures: What to expect in the API’s output
- Rate limits and usage quotas
- Making API Requests: Typically, you’ll send POST requests to the API endpoint. Include your API key in the request headers for authentication and your prompt or query in the request body. The LLM processes this input and returns a response, usually in JSON format.
- Monitor Usage: Keep track of your API calls, as they often count towards usage limits or billing thresholds on a managed service. If you are self-hosting, usage statistics can inform how much you have to scale and how well your application does so
Here’s a simple example of how you can send a request to an LLM using OpenAI’s API in Python:
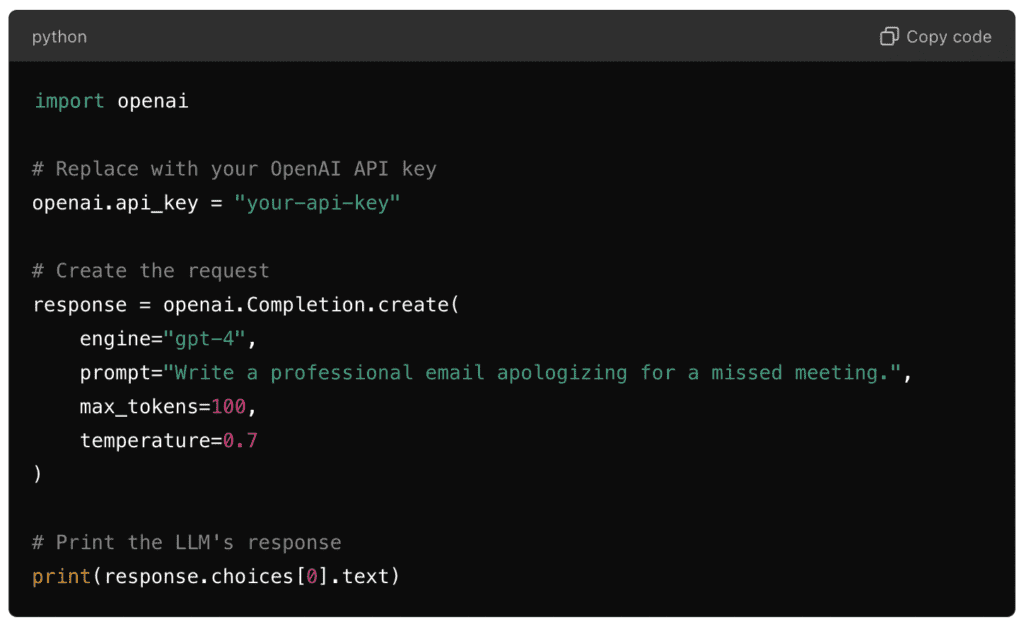
This script authenticates with the API using your key, sends a prompt for the LLM to process, and prints the response.
💡Pro tip: Use a tool like Postman or curl to experiment with API calls before diving into code. It’s a great way to get familiar with the request-response cycle without the overhead of full integration.
Step 3: Implement the Integration
The integration process involves connecting the LLM to your applications, automating workflows, and ensuring that the model can interact seamlessly with your existing infrastructure.
Whether you’re using SDKs, libraries, or custom code, this step ensures that your LLM-powered solutions are fully operational and scalable within your environment.
| Key Integration Methods |
|---|
|
Official Libraries:
|
|
Custom Code:
|
|
Integration Frameworks:
|
How to Connect the LLM with Existing Systems
To connect an LLM to your existing systems, you usually have two options: using pre-built SDKs and libraries or writing custom code.
Which one you choose depends on your technical stack and the level of customization you need.
Using SDKs or Libraries: Most LLM providers offer Software Development Kits (SDKs) or client libraries that simplify integration into popular programming languages such as Python, JavaScript, and Java.
These SDKs provide built-in functions to authenticate API requests, send prompts, and receive responses without writing low-level code.
- OpenAI: The OpenAI Python SDK provides an easy way to interact with OpenAI’s GPT models. This SDK handles everything from setting up the API key to sending prompts and managing outputs.
- Cohere: Cohere’s client libraries support multiple languages and allow seamless interaction with their language models via a simple API.
- Anthropic’s Claude: Claude offers APIs and SDKs that can be integrated into applications across various programming environments.
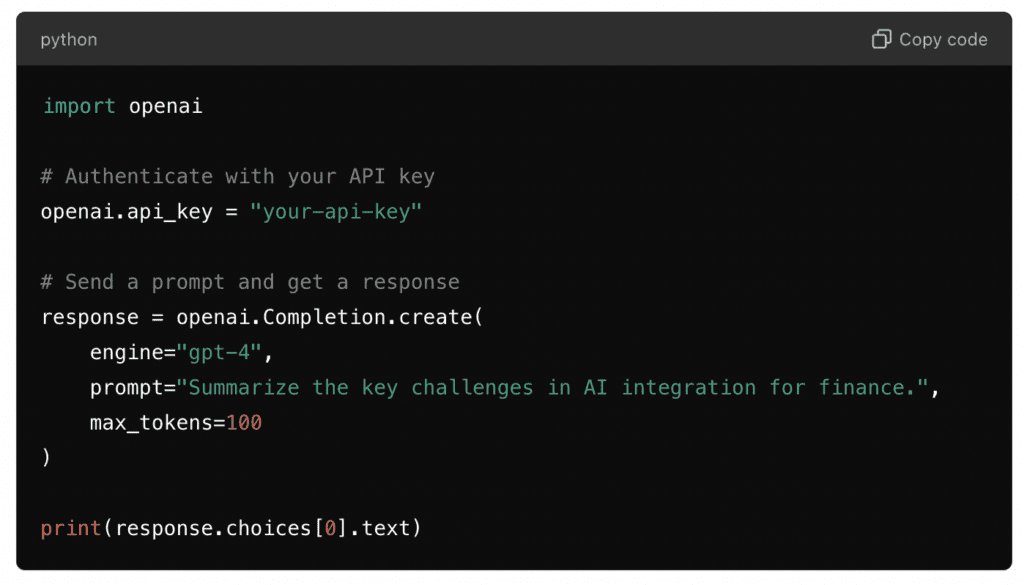
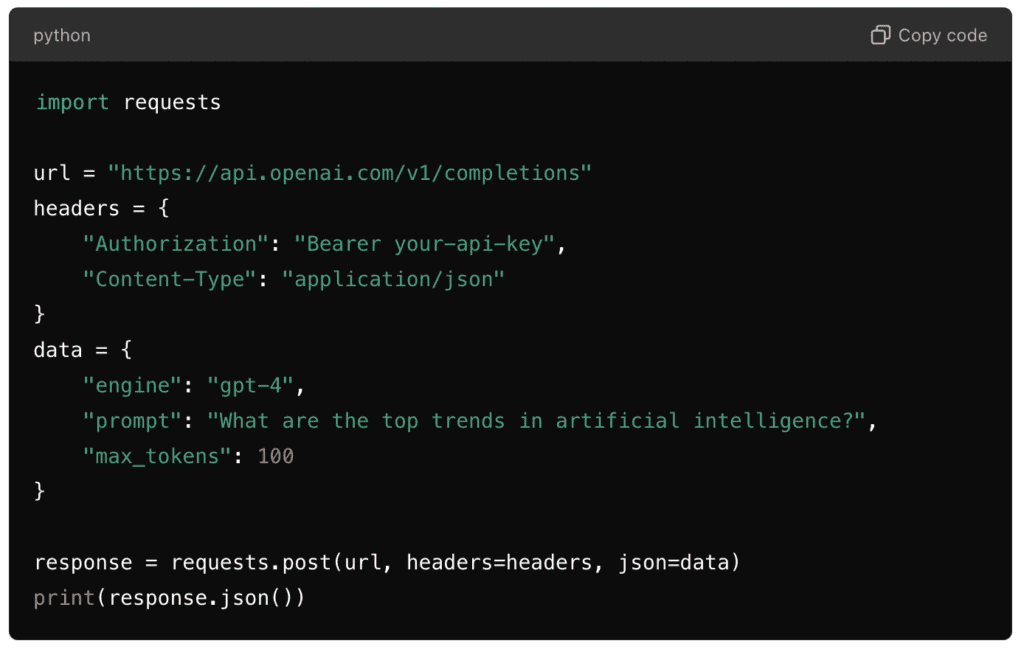
Integration with Common Platforms and Programming Languages: An Overview
Your integration will likely depend on the platforms and programming languages that your business already uses. Fortunately, LLM providers offer broad compatibility with popular systems, guaranteeing the model can integrate into most infrastructures.
Let’s look at a few:
- Python: Python is the most widely supported language for LLM integration due to its popularity in data science and machine learning. Libraries like OpenAI’s Python SDK, Hugging Face’s transformers library, and Cohere’s client make it easy to incorporate LLMs into Python-based applications.
- JavaScript: For web-based applications, JavaScript and Node.js are commonly used. LLM providers typically offer JavaScript SDKs or APIs that allow seamless integration with web apps, customer service platforms, and chatbots.
Example (OpenAI API in Node.js):
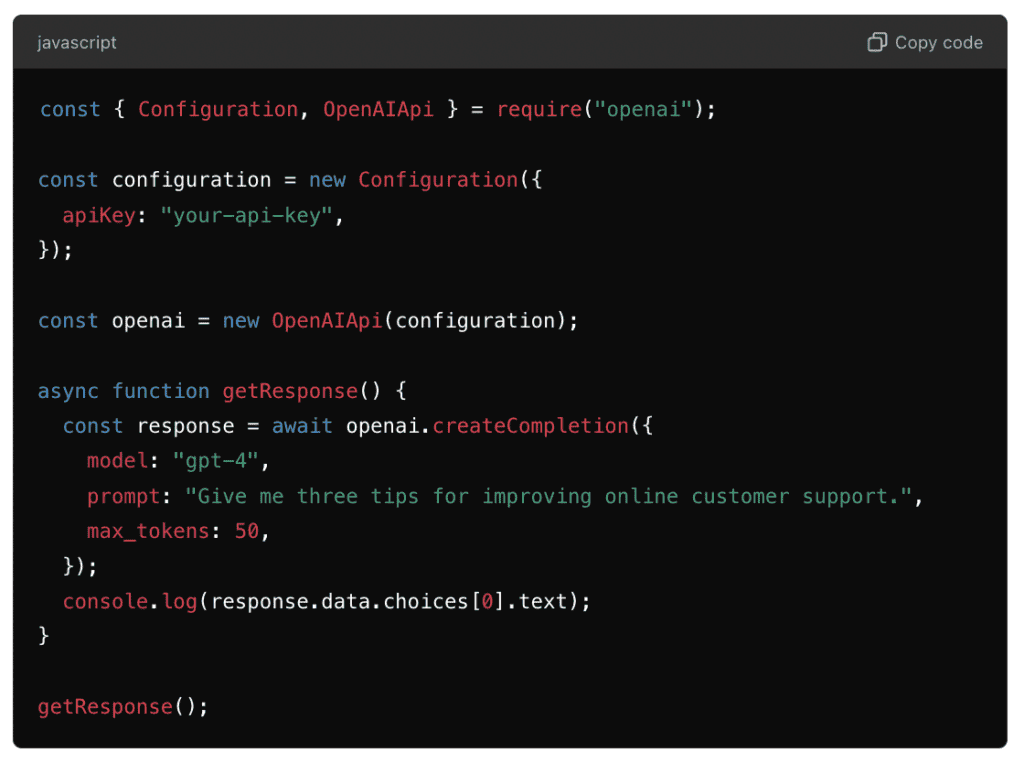
There are also several frameworks and platforms that help streamline the process of integrating LLMs into your business applications.
These tools reduce the complexity of working with LLMs and offer additional functionality like memory management, chaining tasks, and working with multiple models.
| Description | Example | |
|---|---|---|
|
LangChain
|
LangChain is a framework designed to make working with LLMs easier by allowing you to chain together prompts and outputs in a structured way.
It’s useful for tasks that involve complex workflows or interactions, such as building conversational agents or processing multi-step queries.
LangChain abstracts away much of the low-level code involved in handling API requests, making it easier to implement logic-driven interactions.
|
You can use LangChain to build a chatbot that remembers previous interactions or combines LLM-generated responses with external API calls (e.g., retrieving real-time data).
|
|
Hugging Face
|
Hugging Face provides a repository of pre-trained models, including LLMs.
Their transformers library allows developers to quickly integrate models into their applications with minimal code.
Hugging Face also offers Inference API services, allowing you to host and run LLMs without worrying about infrastructure management.
|
Using Hugging Face’s transformers library to integrate a pre-trained GPT-2 model for text generation within your internal business application.
|
|
Azure AI Services
|
Azure AI Services simplifies the process of integrating LLMs into your Azure infrastructure.
It offers tight integration with other Microsoft services, such as Power Automate, Logic Apps, and Cognitive Services.
|
Automating customer service responses by integrating GPT-4 into a Microsoft Dynamics 365 CRM system through Azure OpenAI Service.
|
|
AWS Bedrock
|
Amazon Web Services offers models like Amazon Titan, and you can use AWS services like Lambda, S3, or SageMaker to incorporate these models into business workflows. AWS Bedrock is a managed service that helps you build and scale applications using LLMs.
|
|
|
Google Model Garden on VertexAI
|
Model Garden is a model marketplace, offering a single place to discover, customize, and deploy a wide variety of models from Google and Google partners. It makes it easy to swap models while maintaining the same application code.
|
|
Step 4: Managing Data Input and Output
When integrating LLMs into your business processes, you will encounter various data formats—whether they are free-form text or structured data like tables and databases.
Your challenge is to ensure data input is well-formatted for the LLM to understand and that the output can be processed.
In this step, we’ll:
- cover best practices for handling different data formats
- introduce the concept of Retrieval-Augmented Generation (RAG) to enhance LLM performance with proprietary data
Handling Different Data Formats When Interacting with LLMs
Properly preparing your data before it’s sent to the model ensures that the LLM can interpret it accurately and generate high-quality responses.
Here are some data formats you’ll likely work with and how to manage them:
Text Data:
This is the most straightforward data type for LLMs. It includes natural language inputs such as questions, requests, or product descriptions.
For example, if you’re using an LLM to power a customer service chatbot, the input is typically the text of the customer’s question or complaint.
➡️ Best Practice: Clean your text inputs to remove unnecessary or irrelevant information, such as formatting artifacts, special characters, or overly long queries that may lead to noisy outputs.
Structured Data (e.g., CSV, JSON, SQL):
Many business applications rely on structured data formats, such as product inventories in CSV files, customer databases in SQL, or API responses in JSON.
While LLMs do not natively handle structured data, you can convert the structure into text that the LLM can interpret.
As an example: A JSON file with product details can be flattened and transformed into a text prompt for the LLM: “Product: ‘Laptop X’; Features: ‘16GB RAM, 512GB SSD’; Price: ‘$999’.” This helps the LLM work with structured information.
➡️ Best Practice: Pre-process structured data into human-readable text formats or tables and clearly define what the LLM should extract or analyze from that data.
Unstructured Data (text, images, PDFs, audio, sensor data, log files):
If your business needs to work with unstructured data types (e.g., text with images), you’ll need to combine LLMs with other machine learning models, such as computer vision models, for image recognition. However, some newer LLMs, like GPT-4, can handle both text and images.
➡️ Best Practice: If this type of processing is required, ensure that the inputs are formatted to guide the model in distinguishing between text and other data types. To do that, you can provide clear tags or descriptions for images within the prompt.
Using Retrieval-Augmented Generation (RAG) for Proprietary Data
Many businesses rely on proprietary data that LLMs don’t have direct access to, such as internal reports, historical customer data, or private market analysis.
This is where Retrieval-Augmented Generation (RAG) comes into play.
RAG enhances LLM capabilities by combining the model’s language generation power with real-time access to your proprietary data.
RAG involves querying a retrieval system (e.g., a database or document search engine) that pulls relevant information from your proprietary datasets.
The retrieved data is then fed into the LLM as part of the prompt, enabling it to generate more accurate and contextually informed responses.
Did you know?
You can build-in access control into your RAG system. That means your intern won’t have the same access to data as your CEO and your consultants only see what you want them to see.
At HatchWorks AI we build that into our RAG Accelerator. You can learn more about that here.
Democratize insights for all
Talk to your data in real-time
Prevent AI hallucinations
Create personalized experiences
Secure your data
Maintain control of your proprietary data, ensuring privacy and security without third-party exposure.
Reduce the cost of AI
Step 5: Designing Prompts for Optimal Results
While LLMs like GPT-4 are powerful, they don’t inherently “understand” the context of your business or what you want unless prompted effectively. Well-designed prompts help the LLM generate valuable, actionable responses that meet your business needs.
We have a guide on prompting you can read here.
Below are some of our best practices to follow when creating prompts:
Be Specific and Clear
LLMs respond better when the input is precise. Instead of asking general or open-ended questions, be specific about what you want the model to do. For example:
- Ineffective prompt: “Tell me about AI.”
- Effective prompt: “Provide a brief overview of the current applications of artificial intelligence in healthcare.”
Use Context to Guide the Model
Providing additional context in the prompt helps the model generate more targeted responses. Context could include previous conversations, background information, or clarifying details. For example:
- Without context: “What is the weather like?”
- With context: “I am planning a trip to Paris next weekend. What is the weather forecast for Saturday and Sunday?”
Incorporate Examples
When asking the model to perform tasks like writing, summarizing, or analyzing data, including an example can guide the LLM toward the desired format or tone. For instance:
- Prompt with an example: “Write an email in a professional tone thanking a customer for their purchase. Here’s an example: ‘Dear [Customer Name], Thank you for choosing us. We appreciate your business and look forward to serving you again soon.’
Break Down Complex Queries into Steps
If you’re asking for complex outputs, break the query into smaller, more manageable steps. This helps the LLM tackle the problem systematically and avoid confusion. For example:
- Ineffective prompt: “Can you write a report on market trends and customer behavior for our latest product launch?”
- Effective prompt: “First, summarize the key market trends in our industry. Then, analyze how customer behavior has shifted since our latest product launch.”
Set Clear Expectations for Output
You can control the style, length, or depth of the LLM’s response by setting explicit instructions. You might specify a word count, tone, or response format. For example:
- Prompt with clear output expectation: “Write a 200-word summary of the financial performance of the company in Q3, using a formal tone and focusing on revenue growth and challenges.”
Leverage Parameters like Temperature and Max Tokens
Many LLM APIs allow you to fine-tune the model’s behavior using parameters:
- Temperature controls the randomness of the response. Lower values (e.g., 0.2) make the output more deterministic, which is useful for factual tasks, while higher values (e.g., 0.8) introduce more creative or varied responses.
- Max Tokens sets a limit on how long the response will be. This is important when working within a budget or needing concise answers.
Iterate and Refine Your Prompts
Effective prompt design is often an iterative process. Start with an initial prompt, review the results, and then refine your prompt based on the output. For example:
- Initial prompt: “Describe the benefits of integrating AI in business.”
- Refined prompt: “List three specific benefits of using AI to automate customer service in e-commerce.”
Step 6: Train Your Team and Roll Out the Integration
Successful implementation of LLM technology extends beyond technical integration.
It requires strategic team preparation and a well-planned rollout process to ensure smooth adoption and maximize the technology’s impact on your operations.
Tips for Training Your Team
Understand the Use Case: Start by educating your team on the specific use case for the LLM within your business.
Whether it’s automating customer support, generating marketing content, or assisting with internal decision-making, clarity on the purpose and expected outcomes is essential.
For example, if your LLM is integrated into a customer service chatbot, employees should understand how the LLM handles inquiries, when human escalation is necessary, and how the AI interacts with your CRM system.
Teach Prompt Engineering: A critical aspect of LLM usage is understanding how to design prompts.
Employees should be trained on:
- Crafting specific, clear, and effective prompts.
- Adjusting the tone or style of responses to fit business needs.
- Using advanced parameters like temperature and max tokens (for technical teams).
Conduct workshops or provide examples of common queries and responses to help employees practice prompt crafting. You can refer back to step 5 in this guide for more information on what a good prompt looks like.
Introduce the LLM Interface: Walk your team through the platform or tools they’ll be using to interact with the LLM.
If the LLM is embedded within an existing software (like a CRM or customer service platform), demonstrate how to access it, input prompts, and retrieve outputs.
Need an example? For a customer support team, show how to input customer queries into the LLM system and how to escalate more complex cases to a human agent when necessary.
Rolling Out the LLM Integration
Here’s a framework for a smooth rollout:
Pilot the LLM in a Controlled Environment:
Start with a small-scale pilot in a controlled environment before implementing the LLM across the entire organization. This could be a specific team, department, or customer segment where you can closely monitor the model’s performance and user feedback.
Monitor and Adjust Based on Feedback:
During the pilot phase, collect feedback from both employees and end-users. Track the accuracy and efficiency of the LLM’s outputs, and identify any issues such as common errors, system latency, or inappropriate responses.
Use this feedback to make adjustments, such as refining the prompts, tweaking the LLM parameters, or enhancing the integration with your existing systems.
Scale Gradually:
Once the pilot has been deemed successful, gradually scale the integration to more teams, use cases, or customer segments. This phased approach allows you to catch and address potential issues before they affect the entire organization.
Moving Forward with LLM Integration the HatchWorks AI Way
Ready to realize the potential of your business when powered by AI? You don’t have to do it on your own. We can make the process of implementation smoother for you and your team. You have a few options:- Join our AI Roadmap and ROI Workshop — It’s perfect for finding your use case and you’ll leave with a proof of concept and tailored action plan
- Join our AI Solution Accelerator — You’ll leave with a working prototype of your Generative AI concept
- Get HatchWorks to build your RAG LLM for you from start to finish — Learn more about the RAG Accelerator here.
Further Reading:
- LLM Use Cases: One Large Language Model vs Multiple Models
- Open-Source LLMs vs Closed: Unbiased 2024 Guide for Innovative Companies
- The CTO’s Blueprint to Retrieval Augmented Generation (RAG)
- Gen AI Hacks That Will Cut Development Time in Half: How to Guide
- How to Deploy an LLM: More Control, Better Outputs
- How to Use Small Language Models for Niche Needs in 2024
We’re ready to support your project!
Instantly access the power of AI with our AI Engineering Teams.



