
Tech teams are constantly under pressure to move fast—launch new features, troubleshoot issues, optimize systems—but speed often comes with the risk of costly mistakes and inaccuracies.
Many are turning to Generative AI to help them keep pace with their workload and do more with less but Gen AI alone can only get you so far. It doesn’t pull from proprietary or up-to-date data and it is susceptible to hallucinations.
That’s where RAG (Retrieval Augmented Generation) comes in.
By combining real-time data retrieval with AI-driven insights, RAG goes beyond generative AI to give you the most up-to-date and accurate information.

Whether it’s improving code quality, optimizing cloud resources, or speeding up troubleshooting, RAG ensures your team has the right data when they need it.
In this article, we’ll explore how RAG can streamline operations, improve decision-making, and give your tech teams the competitive edge they need to stay ahead.
RAG (Retrieval Augmented Generation) for Technology: How Do They Fit Together?
RAG merges two powerful AI approaches—retrieval-based and generative models—to deliver highly contextual, real-time information.
The retrieval model pulls relevant, up-to-date data from vast databases (think internal docs, external APIs, and proprietary datasets).
Then, the generative model (like an LLM) takes that info and crafts a response that’s not just accurate, but highly specific to the query.
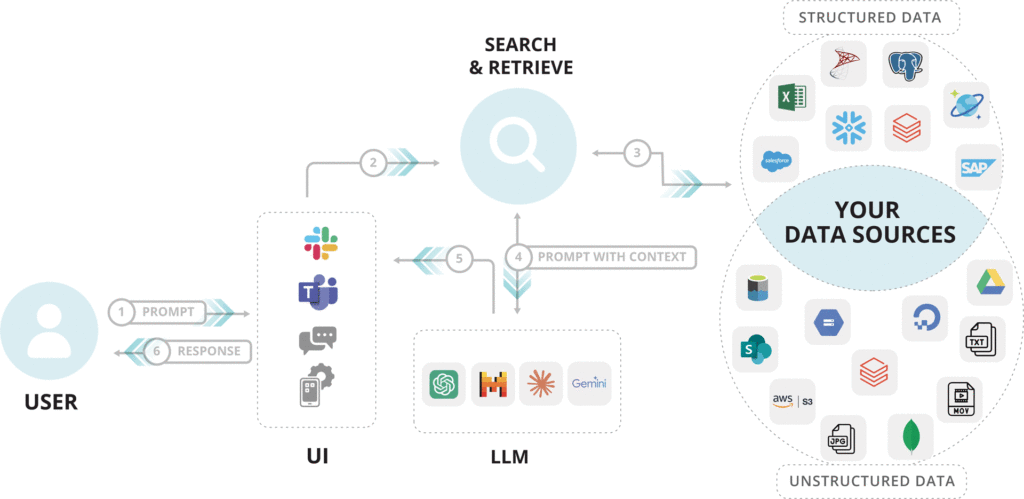
When applied to tech, RAG pulls data from internal sources like system logs, code repositories, and performance metrics, as well as external sources like API documentation, security updates, and market trends.
This lets tech teams generate precise, real-time solutions for tasks like debugging, system optimization, and product development.
📚 Want to learn more about LLMs to inspire your use of RAG? Check out: LLM Use Cases: One Large Language Model vs Multiple Models
RAG vs. Other Technologies
RAG vs. GPT and transformer-based models: Traditional GPT models generate outputs based on patterns they’ve learned from past data.
In tech environments, where new data streams in constantly, this limitation can lead to incomplete or outdated outputs.
RAG pulls live, real-time data continuously—so it doesn’t get left behind.
Whether you’re optimizing server performance, debugging code, or building smarter applications, RAG’s ability to integrate proprietary data into its outputs sets it apart from traditional ML models, ensuring decisions are based on the most current and relevant information
RAG vs. traditional search engines: A traditional search engine (like Google) gives you access to sources and, in some cases, generates a comprehensive response based on what it finds. The issue?
Anyone can access that same data, and search engines rely only on public sources like websites.
RAG, however, pulls from private, proprietary data that no one else has access to. And your team gets unique, actionable insights as a result.
It delivers the exact solution based on the best available data—your data.
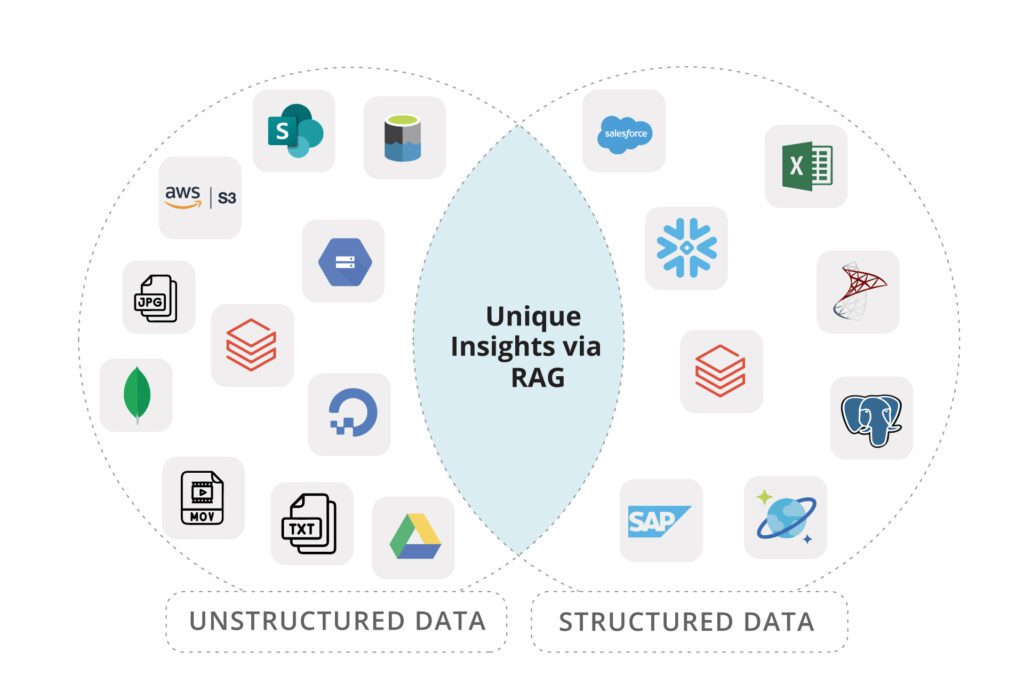
Why High Tech Needs RAG: A Summary
With data flowing in from every direction—system logs, performance metrics, API updates, user feedback—tech teams juggle a lot of information at once.
Yet the pressure is on to make real-time, data-driven decisions. Whether it’s optimizing infrastructure, debugging code, or developing new features, delays and errors can cost serious time and money.
RAG simplifies this process. It pulls together critical data from internal systems and external sources, allowing you to create seamless, context-aware solutions in real time.
Need to troubleshoot an application crash? RAG retrieves relevant logs, combines them with up-to-date documentation, and generates actionable insights in seconds.
And while speed is critical, security is essential.
RAG keeps proprietary data under your control, ensuring that sensitive information stays secure while still being leveraged for smarter decision-making.
The only question left is: how do you implement RAG in your environment?
At HatchWorks AI, we can do it for you—securely and efficiently.
Get in touch here if you want us to build your RAG-based solution or want us to train your tech team how to build it for themselves.
Secure and Certified with SOC 2 Type I and HIPAA
 At HatchWorks, trust and compliance are paramount. We adhere to the highest security standards, evidenced by our SOC 2 Type I and HIPAA certifications.
At HatchWorks, trust and compliance are paramount. We adhere to the highest security standards, evidenced by our SOC 2 Type I and HIPAA certifications.
These certifications, verified through independent audits, ensure our systems are secure and your data is protected under strict privacy regulations. Stay informed with our real-time TrustCloud compliance program.
Benefits of RAG in the Tech Sector
Let’s look more closely at how RAG can benefit your work in tech.Enhancing speed and accuracy in tech operations
RAG gives you instant access to relevant information, so you can fix problems fast and spend less time searching for answers.
For example, a developer facing a server issue can use RAG to instantly pull performance metrics and log data, quickly identifying the root cause of the problem.
This leads to faster troubleshooting and minimal downtime.
Empowering tech teams with real-time, context-driven insights
RAG pulls real-time insights from both internal and external sources, giving developers, engineers, and data scientists the context they need to make smarter decisions on the spot.
You can say goodbye to second-guessing or chasing outdated info because you’ll trust what you have access to.

Better decision-making in complex, data-driven environments
Tech teams are juggling a ton of data, and making the right call can be tough. RAG simplifies that by pulling from multiple data streams to deliver comprehensive, reliable insights.
This means less guesswork and more informed decisions, whether you’re optimizing cloud resources or tackling complex coding issues.
Overcoming Challenges
Of course, RAG models come with their own set of challenges. Here are three key issues that tech teams often face when implementing RAG, and practical ways to overcome them.
Challenge 1: Handling proprietary data in RAG models
Using proprietary data in RAG applications can raise concerns around security and privacy, especially when dealing with sensitive tech information like intellectual property or customer data.
Without the right safeguards, you run the risk of exposing critical data to vulnerabilities.
How to overcome it: The key is implementing strict access controls and encryption protocols for both the data and the RAG model itself.
Additionally, running RAG on a secure cloud infrastructure or on-premises server ensures that data remains within your control.
Regular audits and compliance checks are also essential to ensure your systems stay secure.
Challenge 2: Scaling RAG across large tech ecosystems
Deploying RAG across multiple tech teams or platforms isn’t always straightforward.
The challenges of scaling RAG models across a large, distributed ecosystem often lead to inconsistent results or integration issues. Managing different data sources, workflows, and outputs can make this even harder.
How to overcome it: Start by rolling out RAG on a smaller scale with a pilot project, focusing on one high-impact use case to test integration with your existing tech stack.
Once proven, gradually scale it across other teams and departments, while keeping infrastructure and workflows standardized to avoid fragmentation.
Challenge 3: Ensuring RAG model accuracy and reducing bias
While RAG pulls data from various sources, there’s always a risk that the retrieved information could be inaccurate, incomplete, or biased—especially in complex, data-driven environments.
If not carefully managed, this can lead to biased outputs or flawed insights that affect decision-making.
How to overcome it: It’s essential to regularly audit the datasets RAG models pull from to ensure diversity and representativeness.
Using bias detection algorithms can also help flag and correct any problematic patterns in the data retrieval process.
On top of that, keeping your data sources fresh and up-to-date is important if you want to maintain accuracy over time (which of course you do!).
How RAG Can Be Used in Tech: Key Applications & Use Cases
Tech is a pretty broad industry, so let’s cover the different ways RAG can actually be used to put your team and your business ahead.
Optimizing Software Development
Code Generation and Completion
RAG helps developers write code faster by pulling in context-aware suggestions and auto-completions from both internal and external sources.
Example: A developer using RAG with GitHub gets relevant functions from open-source libraries, speeding up development and reducing manual work.
Debugging with Enhanced Efficiency
When bugs pop up, RAG retrieves the right error logs, documentation, and past fixes, saving time and frustration.
Instead of manually searching through old reports, developers can focus on resolving issues faster with real-time data at their fingertips.
Example: A developer uses RAG to pull from a knowledge base of previous errors and instantly finds the solution to a recurring bug, reducing time spent on troubleshooting.
Automating Repetitive Coding Tasks
Tired of generating boilerplate code? RAG automates repetitive tasks like code generation or refactoring, allowing developers to focus on what matters most—building great products.
Example: A team uses RAG to automatically generate framework-specific boilerplate code, freeing developers from repetitive manual coding tasks.
Enhancing Data Science Workflows
Data Retrieval for Model Training and Analysis
RAG makes it easy to pull accurate datasets from various sources, both internal and external, so data scientists spend less time searching and more time analyzing.
With fresh data readily available, your models get trained on the most relevant information.
Example: A data scientist uses RAG to access up-to-the-minute proprietary and open-source datasets, improving the accuracy of their predictive model.
Automating Feature Engineering
RAG can dig through huge datasets, surfacing important features and patterns to help automate parts of feature engineering.
This cuts down on manual exploration and leads to quicker insights.
Example: During exploratory data analysis, RAG identifies important feature correlations from past datasets, speeding up the feature engineering process.
Integrating RAG into Data Pipelines
With RAG integrated into your data pipeline, retrieving and prepping data from large databases or APIs becomes automatic. That means less manual work and cleaner, ready-to-use data for your models.
Example: A team integrates RAG to pull and clean real-time data from multiple APIs, cutting down on the manual effort involved in data preprocessing.
Optimizing Cloud and Edge Computing
Improving Real-Time Data Retrieval and Processing
RAG pulls the data you need faster, so cloud-based AI services and applications can keep up with real-time demands.
Whether it’s managing storage metrics or handling system data, RAG ensures you get the right info without delay.
Example: A cloud engineer uses RAG with AWS to automate the retrieval of cloud storage metrics, improving real-time monitoring and processing.
Handling Large-Scale Distributed Data
When dealing with large datasets spread across multiple locations, RAG steps in to manage and retrieve data more efficiently.
It reduces lag, keeps systems running smoothly, and ensures better access to distributed data.
Example: A company uses RAG to manage and retrieve distributed data across multiple cloud locations, optimizing system latency and throughput.
Optimizing Edge Computing Operations
At the edge, RAG delivers real-time data from cloud sources and local sensors, helping IoT systems and autonomous devices make smarter decisions on the spot.
Example: RAG helps a smart factory’s IoT system make real-time decisions by pulling operational data and sensor metrics from the cloud and adjusting resource allocation as needed.
Enhancing Hardware and IoT Systems
Improving Decision-Making for Smart Devices
RAG allows smart devices to make better choices by retrieving data from sensors, logs, and cloud systems.
Whether it’s a smart home or an industrial IoT setup, RAG ensures systems get the right data when they need it.
Example: In a smart home, RAG integrates data from multiple IoT devices to recommend energy-efficient settings based on real-time sensor inputs.
Automating Hardware Configurations and Optimizations
RAG pulls performance data and previous configurations to keep hardware systems running smoothly.
By automating these adjustments, your hardware always operates at its best without manual intervention.
Example: RAG optimizes server performance by automatically pulling historical configurations and adjusting resources based on current usage.
Managing Hardware Diagnostics and Maintenance
With RAG, hardware diagnostics and maintenance become more streamlined. It pulls logs, repair histories, and diagnostic data, allowing for predictive maintenance and quicker fixes.
Example: An industrial company uses RAG to predict when their machines need maintenance by analyzing repair logs and sensor data.
Accelerating AI and ML Innovation
Improving AI Model Training with Smarter Data Retrieval
Training AI models becomes easier with RAG, which ensures that only relevant, high-quality data is retrieved. This improves the training process, reduces the time it takes, and boosts model accuracy.
Example: A machine learning team uses RAG to pull real-time data from proprietary datasets, reducing training times and improving model performance.
Enhancing Natural Language Processing (NLP) Systems
RAG helps NLP systems provide more accurate, context-aware responses by retrieving relevant real-time data.
This makes AI assistants, chatbots, and customer service tools more reliable and less prone to errors.
Example: A virtual assistant powered by RAG retrieves relevant customer data and external updates, offering more precise answers to complex queries.
Optimizing Cybersecurity Efforts
Using RAG for Real-Time Threat Detection
RAG scans security logs, threat databases, and external sources in real-time to detect vulnerabilities and potential threats before they become an issue.
Example: A cybersecurity team uses RAG to monitor real-time network activity and detect anomalies that could indicate a breach.
Enhancing Incident Response Systems
When a security breach happens, RAG helps teams act faster by retrieving past incident reports, real-time threat data, and relevant documentation.
This speeds up response times and improves accuracy.
Example: A company integrates RAG with its threat intelligence platform to quickly pull the latest threat information and take action in real-time.
What Will Your RAG Use-Case Be?
Now it’s time to consider how RAG can make a difference in your tech operations.
Start by asking yourself: Where in your business would faster, more accurate information have the biggest impact?
Think about areas where decisions rely on vast, complex data streams—such as software development, cloud management, or cybersecurity. And where proprietary data especially can help.
For example, if reducing downtime is a top priority, RAG could enhance your monitoring systems by pulling relevant real-time performance metrics and providing instant insights.
Or, if improving threat detection is key, RAG could continuously retrieve data from external threat databases and apply that to your existing security protocols.
Next, collaborate with stakeholders such as engineering leads, IT teams, and project managers to validate your RAG use-case ideas.
Make sure everyone is aligned on how integrating RAG into workflows can enhance productivity, reduce errors, or improve decision-making across your tech ecosystem.
The Road Ahead: RAG’s Future in Tech
When it comes to RAG, the future is full of exciting possibilities.
One area to watch is the integration of RAG with next-gen technologies like quantum computing and 6G. With quantum processing, RAG could access and analyze massive data sets at lightning speed, making real-time decision-making even faster and more accurate.
As AI-driven technology evolves, RAG will play a key role in powering smarter automation, advanced decision-making, and intelligent systems.
Picture RAG enhancing self-driving cars, or optimizing cloud systems in real time with data pulled from a global network.
We’re also expecting big jumps in RAG’s efficiency and accuracy. Future systems will be more scalable, faster, and able to handle complex data streams with ease, leading to more reliable outcomes and a new era of intelligent tech solutions.
Introducing the RAG Accelerator: HatchWorks AI’s Solution to Your RAG Needs
Excited to integrate RAG into your tech stack but not sure where to start?
At HatchWorks AI, we offer the RAG Accelerator—a fully managed solution that lets you capitalize on the capabilities of RAG without taking the time to build and integrate it yourself. It’s perfect for tech teams who don’t know how to implement it and don’t have the time to if they did.
Our RAG Accelerator includes:
- Customized RAG solutions tailored to your specific tech environment and needs
- Seamless integration into your current systems and workflows, with minimal disruption
- Ongoing support and updates, so your RAG implementation stays fast and cutting-edge
- Full data security and compliance, ensuring your sensitive information remains protected
Want to learn more? Visit our service page to learn more about how we can tailor a RAG solution for your organization, or contact us directly to schedule a consultation.
Other AI resources you might like:
- How to Deploy an LLM: More Control, Better Outputs
- How AI as an Operating System is Shaping Our Digital Future
- Embrace Generative AI in 2024: A Detailed Guide for Seamless Team Integration
- RAG: What YOU Need to Know to Apply AI at Work
- The CTO’s Blueprint to Retrieval Augmented Generation (RAG)
- RAG in Financial Services: Use-Cases, Impact, & Solutions
- Harnessing RAG in Healthcare: Use-Cases, Impact, & Solutions
- RAG for Retail: Use-Cases, Impact, & Solutions
- RAG for Communications: Use-Cases, Impact, & Solutions
Turn Your Data Into a Differentiator
Access the power of AI in your enterprise with our RAG Accelerator.



