
This Article at a Glance:
Real-time, personalized conversations with your company’s proprietary data—that’s what retrieval augmented generation (RAG) is capable of. Level up your use of Generative AI by generating more timely, accurate, and bespoke outputs.
You also have an asset no one else in your industry can use because it’s completely unique to you – your data.
In this article, you’ll learn the what and how of retrieval augmented generation along with examples of how it can be used. There’s also an explanation of how we at HatchWorks AI can help you implement retrieval augmented generation successfully.

Artificial Intelligence just keeps getting, well, more intelligent. This progression in AI technology is reshaping what’s possible with its use. And alongside this evolution is the introduction of new AI-based solutions like Retrieval Augmented Generation (RAG).
Retrieval augmented generation isn’t the driving force behind AI’s increasing intelligence, but rather a powerful method that combines advanced AI with your data to enhance AI applications.
Without your company’s specific data, AI responses can be as generic as a horoscope. RAG changes that, grounding AI outputs in real-time, relevant info.
But, how? What does RAG even mean? And how can I use it in my business?
In this guide, we’ll cover:
- What is RAG and How Does It Work?
- RAGs Key Benefits (For AI and for Business)
- What to Be Wary of with RAG
- How to Set up RAG
- RAG in Various Industries: Inspiration for Your Use
- FAQs about RAG
- Get HatchWorks to Implement and maintain RAG on Your Behalf
Would you rather have someone implement RAG into your business on your behalf?
Check out our RAG Accelerator, where we get a RAG system up and running so you get a solution that taps into your data in real-time.
What is Retrieval Augmented Generation (RAG) and How Does It Work?
First, let’s clear up that acronym.
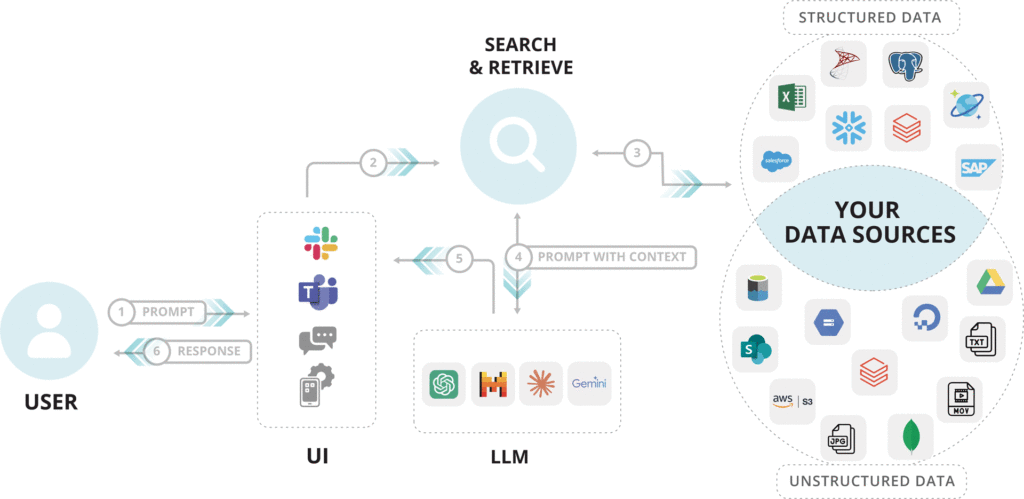
RAG stands for Retrieval Augmented Generation. It improves the output of Large Language Models (LLMs) by combining its natural language processing capabilities with a semantic search and retrieval system.
ℹ️ What is RAG?
Retrieval Augmented Generation (RAG) is a technique that improves the responses of AI language models by combining them with a search system.
This search system looks through a large collection of documents to find relevant information. This collection can be based on your proprietary company data that an LLM would never have access to on its own. By using this company information, the AI search engine can give more accurate and up-to-date answers, instead of relying only on what it already knows.
Retrieval augmented generation is great to use when factual accuracy and current information are important.
By blending static knowledge bases with dynamic retrieval, it allows businesses and organizations to stay ahead, delivering precise insights based on the most recent data.
Think of a hospital being able to search a patient’s updated medical records and the most recent medical research to reach a diagnosis.
How RAG Operates 🤖
Retrieval augmented generation works in two stages. First, it retrieves relevant information from a vast dataset or an external source. Then, it leverages a LLM (large language model) to craft responses that are both accurate and context-aware.
Key elements of retrieval augmented generation include vector databases, which store and retrieve data efficiently, and NLP models (like GPT) that generate natural language text.
RAG vs Large Language Models (LLMs): What Exactly is the Difference?
Unlike traditional LLMs that generate responses solely from their training data, RAG pulls in relevant information from external sources, like databases or the web, to craft contextually accurate and up-to-date responses to user query.
They exist in tandem. So it’s not a case of ‘one vs the other’, it’s ‘what is an LLM capable of and how can RAG make it more capable?’.
But wait, can’t we fine-tune an LLM to be trained on new data? You can and at HatchWorks we are huge champions of fine-tuning LLMs. We even had a webinar about it, you can watch here.
Fine-tuning is important to adapt your LLM to your specific domain, improve accuracy for specialized tasks, and customize specific output. But if it’s all you’re doing, your system won’t have access to your real-time data. Plus you will need to continuously fine tune it.
That’s why you should use both fine-tuning and retrieval augmented generation. With RAG, your LLM can search through an ever-changing database. This keeps your LLM capable of specialization and pulling from real-time information.
📚Curious to learn more about LLMs? You may also like:
RAGs Key Benefits (For AI and for Business)
Democratize insights for all
Talk to your data in real-time
Prevent AI hallucinations
Create personalized experiences
Secure your data
Maintain control of your proprietary data, ensuring privacy and security without third-party exposure.
Reduce the cost of AI
RAG makes AI more accurate and efficient. That accuracy and efficiency trickles down to your business operations, making your team more productive and your AI use cases more reliable.
Let’s look a little closer at how that works.
Enhanced Accuracy:
Traditional AI models often “hallucinate” or generate plausible-sounding but incorrect information.
RAG minimizes this by pulling in verified facts from trusted databases or live web searches, ensuring the AI outputs are reliable and fact-based. When properly configured, RAG workflows allow the AI developer to set a confidence threshold, making sure that sensitive data or topics are treated with extra care for accuracy.
This is important in areas where precision is key, like healthcare, finance, and customer service, where incorrect information can lead to costly mistakes or lost trust.
Increased Efficiency:
Instead of spending hours manually searching for data or reviewing documents, RAG-powered LLMs can instantly provide relevant, contextual information tailored to specific queries. This requires the data be already prepared and ingested, of course – a major hurdle that our RAG Accelerator aims to help with.
This speeds up workflows, reduces operational costs, and frees up your people to focus on more strategic tasks.
For businesses, this means being able to respond quickly to market changes, customer inquiries, or internal needs, all while maintaining a high standard of accuracy.
What to Be Wary of with RAG
RAG’s biggest drawback is that it’s resource-intensive and can incur significant computational and financial costs.
On top of that, integrating multiple models adds complexity, making systems harder to maintain and update over time.
You also need to consider data security if you’re integrating sensitive company or personal data into the LLM.
But don’t let any of that stop you from realizing the potential of RAG in your own business. With HatchWork’s RAG Accelerator, you get a scalable solution that controls costs and grows with your needs.
The efficiency gains will quickly lead to a strong ROI, making your investment in RAG well worth it.
Plus, you won’t have to handle the complexity because we’ll handle it for you. Our RAG solutions are easy to maintain and we offer support to ensure smooth updates, so your team can focus on business goals, not the tech. Handover has never been smoother.
And finally, we take customer data security seriously. Our solutions are SOC2 Type 1 and HIPAA compliant, with strong encryption and secure access controls. That way an intern would have access to the same information as your CEO. We know your data is important and we ensure it is protected and meets industry standards.
How to Set up RAG with Vector Databases and Relevant Documents
Setting up RAG AI can seem complex, but with the right tools and a clear plan, you can get it running smoothly.
Expert tip:
Want to save yourself the time and hassle of setting up RAG yourself or getting your team to do it?
At HatchWorks AI we’ve built a service around implementing RAG into a company’s AI solutions. It helps them leverage their biggest differentiator—their own data.
Learn more about our RAG Accelerator here or get in touch today to explore your options.
Here’s what you need and a step-by-step guide to help you get started.
What You’ll Need: A Basic Checklist
Tools and software you may need include:
- Vector Database: A vector database like Pinecone, Faiss, or Weaviate is essential for storing and retrieving unstructured data efficiently based on similarity.
- Generative Model: A pre-trained NLP model such as GPT-4 (available from OpenAI or Hugging Face).
- Retrieval Software: Use retrieval tools like ElasticSearch or Haystack to index and search your documents. Alternatively, equip your agent with capabilities to convert Text-to-SQL or hit an API for more robust querying capabilities.
- Development Environment: Python is commonly used, so ensure you have a Python environment set up (Anaconda or a virtual environment can help).
- APIs and Integrations: Access to OpenAI API or Hugging Face Transformers, and vector database APIs.
You also have infrastructure requirements, such as:
- High-Performance Computing Resources: A server or cloud-based setup with sufficient CPU/GPU power and memory.
- Storage: Adequate disk space for the vector database and the retrieval index.
- Internet Connectivity: Stable and fast internet access, especially if using cloud-based tools or APIs.
The Steps You’ll Follow
We have a more in-depth look at this whole process in our article, How to Deploy an LLM Locally: More Control, Better Outputs. Below, we have a simpler version that focuses on the RAG element to serve Q&A against a company’s HR knowledge base.
Step 1: Set Up Your Environment
First, you need to build an environment where you can integrate RAG with an LLM.
Here’s what you’ll need:
- An IDE like Visual Studio, along with version control (Git), to streamline your workflow.
- LangChain for streamlined LLM integration, and libraries like torch, transformers, and faiss-cpu.
- A vector database such as Epsilla for efficient embedding storage and retrieval, if dealing with unstructured data. In this example, we will be.
- Pre-trained models (e.g., Mistral), and an inference engine like Llama CPP.
Here’s what you might need:
- A powerful GPU.
You don’t need a GPU unless you’re doing fine-tuning or heavy tasks—just invoking an existing LLM doesn’t require it. If you are doing fine-tuning, you can use cloud services like AWS or Google Cloud for on-demand GPU access—no physical hardware necessary.
Step 2: Prepare Your Data
You need to identify and prep your data source—the one your RAG is retrieving from. This could be internal documents, public datasets, other data sources, or external data from the internet.
It’s important to clean and preprocess your data for efficient indexing. Convert documents to a machine-readable format (like JSON or CSV).
Step 3: Set Up Your Vector Database
If dealing with unstructured data, you then need to choose and set up a vector database.
Use vector embeddings (from models like Sentence Transformers or OpenAI Embeddings) to transform your data into vectors and store them in your vector database for quick retrieval.
Step 4: Configure the Retrieval System
Install ElasticSearch or Haystack for document retrieval keyword search. These tools allow you to perform searches over your indexed data.
It will be helpful to set up indexes in your retrieval tool to show search results and enable quick searching and ranking of documents.
Alternatively, create tools within your Agent to access other retrieval tools. For example, set your agent up to use HTTP to communicate with APIs or SQL to query Databases.
Step 5: Integrate with the Generative Model
Now it’s time to connect your solution to the LLM of your choice to connect your generative model with the retrieval system.
These can be open-source LLMs like Llama or closed-source like GPT4. If you need help finding a model, check out the Hugging Face repository.
Finally, you’ll set up pipelines that retrieve relevant documents, and then pass them to the generative model to generate relevant responses back.
RAG in Various Industries: Inspiration for Your Use
Wondering how RAG could be used in your workplace? Here are some ways RAG can be used across different industries. If your industry is listed you can steal the idea, if it’s not then you can take inspiration.
Customer Support
RAG can improve customer support by automating responses to common queries.
This reduces the time customers spend waiting for answers and improves overall satisfaction. By integrating RAG, companies can ensure that customers receive prompt and accurate information, cutting down the workload for human agents.
👉 Explore more: RAG for Communications: Use-Cases, Impact, & Solutions
Healthcare
RAG can analyze medical records and pull relevant data to assist doctors in diagnosing conditions.
This technology helps healthcare professionals provide better care and make more informed decisions.
👉 Explore more: Harnessing RAG in Healthcare: Use-Cases, Impact, & Solutions
Financial Services
In financial services, RAG can analyze large datasets to identify patterns indicative of fraudulent activities.
It could also analyze market data and trends, helping financial institutions assess risks more accurately.
👉 Explore more: RAG in Financial Services: Use-Cases, Impact, & Solutions
Manufacturing
By analyzing data from various stages of the production process, RAG AI can identify defects and suggest improvements. This enhances product quality and reduces waste.
It could even monitor and adjust production parameters in real-time to maximize efficiency.
If you need help with supply management, RAG AI can predict demand, optimize inventory levels, and streamline logistics. This reduces costs and improves customer satisfaction.
FAQs about RAG AI
What is RAG used for?
RAG (Retrieval-Augmented Generation) is used to generate more accurate, context-aware responses by combining retrieval of relevant response data with natural language generation.
This approach allows AI systems to access and utilize up-to-date information, enhancing their ability to answer questions and provide relevant and informed answers.
What is the difference between RAG and an LLM?
RAG uses real-time retrieval to enhance the output of generative models, while an LLM (Large Language Model) relies solely on pre-existing training data.
This means RAG can access and incorporate the most current information available in its knowledge base, whereas an LLM is limited to the data it was trained on, which may become outdated over time.
What is LoRa vs RAG?
LoRa (Low-Rank Adaptation) is a technique for fine-tuning models, while RAG focuses on dynamic data retrieval and generation.
LoRa is used to efficiently adapt pre-trained models to specific tasks or domains by updating a small number of parameters. RAG, on the other hand, augments model outputs with relevant information retrieved from an external knowledge base.
Is RAG better than fine-tuning?
To answer that question we need to clarify what fine-tuning is. Fine-tuning is the process of taking a pre-trained model and further training it on a specific dataset or for a particular task. This process adjusts the model’s parameters to better suit the target application, potentially improving its performance for that specific use case.
RAG is not necessarily “better” than fine-tuning but different; it’s more suitable for situations where real-time information could help you create more accurate outputs.
And it can be used in tandem to create a more capable, real-time solution that taps into your proprietary data.
Here are some key considerations and how it impacts your choice:
- Flexibility: RAG allows for easy updates to the knowledge base without retraining the entire model, making it more adaptable to changing information.
- Transparency: With RAG, it’s easier to trace the source of information used in generating responses.
- Up-to-date information: RAG can access the most current data in its knowledge base, whereas fine-tuned models are limited to the data they were trained on.
- Task-specific performance: Fine-tuning can lead to better performance on very specific tasks where the model needs to learn particular patterns or domain knowledge.
The choice between RAG and fine-tuning often depends on the specific use case, the nature of the data, and the desired balance between adaptability and task-specific optimization.
Get HatchWorks to Implement RAG on Your Behalf
Your data is your differentiator and we want to help you use it. But getting up to speed on all things AI is time-consuming and comes with hours of trial and error.
We’ve been there, done that, and can create a custom RAG solution for you.
Head to our service page to learn more about how we can help you leverage your data in AI.
Turn Your Data Into a Differentiator
Access the power of AI in your enterprise with our RAG Accelerator.



