
As AI rapidly develops so too does the vocabulary surrounding it.
To effectively implement AI into your business, you’ll need to learn the lingo—AI Inference, training, and fine tuning included.
In this article, I explain what those words mean and how to get the most out of them while investing the least amount of time and money.

👋Hi, I’m David Berrio, Senior ML/AI engineer here at HatchWorks AI. I’m obsessed with all things AI and language models, spending much of my time learning how to leverage them to improve client software projects, our own processes at Hatchworks AI, and my personal hobbies.
Short on time? Get the highlights with these three key takeaways:
- Training an LLM is like awarding an LLM a high school diploma. Fine tuning it is like making them a college graduate. And inference is where they apply all they’ve learned into their career.
- You don’t need to build your own LLM. There are plenty of people who have spent the time and money so you don’t have to. Instead, fine-tune one that already exists and tailor it to your business.
- AI Inference is where the real-world impact happens. It’s the process of applying a trained and fine-tuned model to make predictions or decisions quickly. The speed and accuracy of inference can significantly enhance user experiences and business operations.
Watch the full webinar:
This article is based on my 30-minute webinar on the same topic where I walk you through these definitions and an example of fine-tuning an LLM to niche needs.
📽️ Watch it here.
Training, Fine Tuning, and Inference AI? Core Concepts at a Glance
First up are our three definitions:
Training
When we say training, we’re referring to training and LLM (large language model). It’s the foundational step where a model acquires its general knowledge and natural language processing abilities.
Fine-Tuning
This is the iterative process of taking a pre-trained model and training it further on specific tasks using a smaller, task-specific dataset to adapt it for a particular use case.
AI Inference
Inference is the phase where a trained AI model generates outputs that are completely original using the context of the prompt.
It can be helpful to think of these three concepts as building blocks.
At the base, you need an LLM which is trained. Then as training progresses, you can tune it to your specific needs. And finally, it can be made to ‘think’ and make more complex decisions on its own.

Now let’s dig deeper into each concept to understand how they work, why they’re important, and most importantly, what you can do with them.
Training LLMs—What, Why, and How?
Let’s start by saying an LLM without training can’t make sense of any prompt you put into it.
Training involves feeding thousands if not billions of parameters more data into the system’s algorithm.
Andrej Karpathy, co-founder of Open AI, described it as ‘compressing the internet’.
I like to think of it as giving your LLM a high school diploma. It takes on vast general knowledge from the internet but it is far from an expert in any of the topics it has ‘studied’.
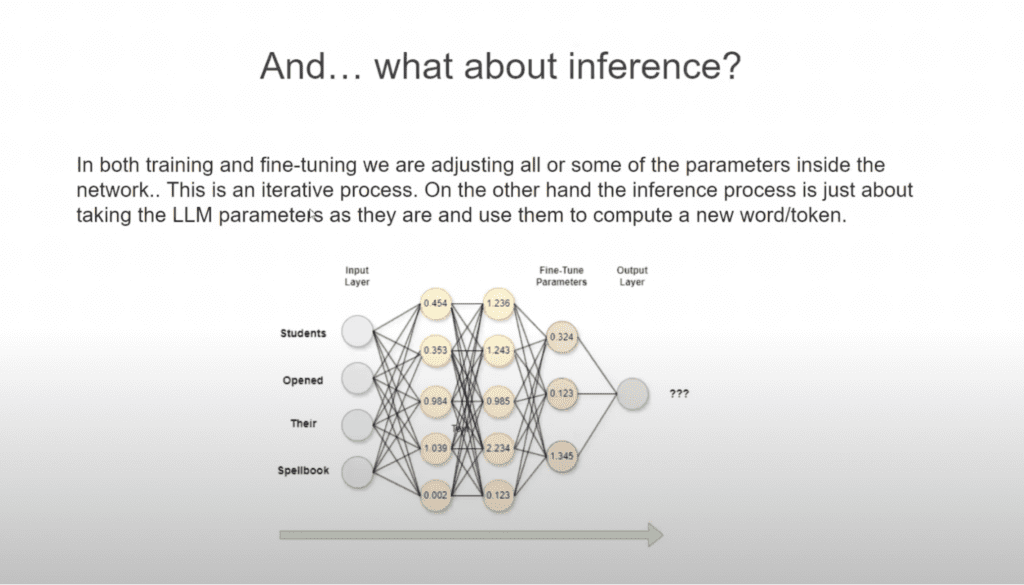
If you look at the image below, you’ll see two visual representations of LLMs. The one on the left shows an LLM before training while the one on the right shows an LLM that has been trained:
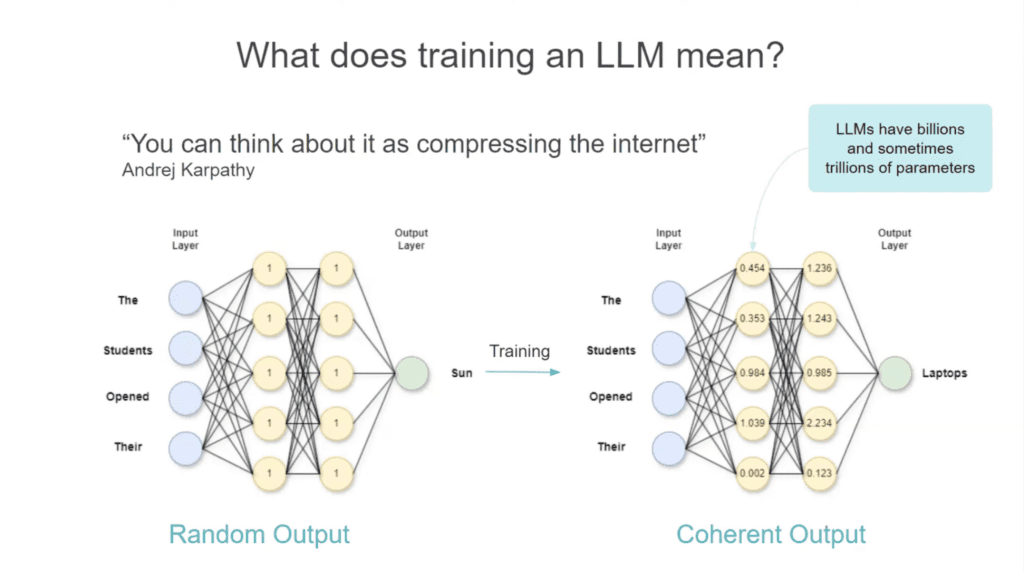
An untrained LLM will take your input (‘The’ ‘Students’ ‘Opened’ ‘Their’) and give you a random and irrelevant output (‘Sun’). It doesn’t know how to apply context to your input to come up with something accurate.
A trained LLM will take that same input data and come up with a coherent, relevant output (‘Laptops’) because it has been trained to read the input. The yellow circles show the neural network which holds knowledge from the internet.
Think of those yellow circles like knobs on a DJ set. You want to tune them to the right channel to get the sounds—or outputs—you need.
The challenge with training your own LLM is you need massive datasets, large datasets that are big enough to give the LLM an understanding of the world. And you need to guarantee that data is high-quality and diverse.
On top of that, training an LLM is incredibly resource-intensive and requires massive computational power, typically using high-performance GPUs or TPUs.
Cloud computing services like AWS, Google Cloud, or Azure can add up quickly. For example, OpenAI’s GPT-3 is estimated to have cost millions in computational resources alone.
Do you need to train your own LLM to use AI successfully? Probably not.
In most cases, leveraging pre-trained, open-source models is sufficient. These trained models, available from organizations like OpenAI, Hugging Face, and others, have already undergone extensive training and can be fine-tuned to meet specific needs.
Be cautious of anyone suggesting that training an entirely new LLM is necessary; it’s often an expensive and resource-intensive training process that many companies don’t require and can’t pursue without extensive computational resources.
Interested in all things large language models? You’ll love these resources:
‘Fine-Tuning’ a Model’s Performance—What, Why, and How?
If training an LLM is making it capable of relevant and useful outputs, isn’t fine-tuning the same thing?
Well, yes and no. You’re taking a pre-trained model (Llama 3, GPT-4, etc.) and training it further on a specific task or a new dataset.
If initial training an LLM gives it a high school diploma, fine-tuning gives it a university degree.
Its specialism can be on anything. That includes information about your product and services, the needs of your customer demographic, and even complex Python code.
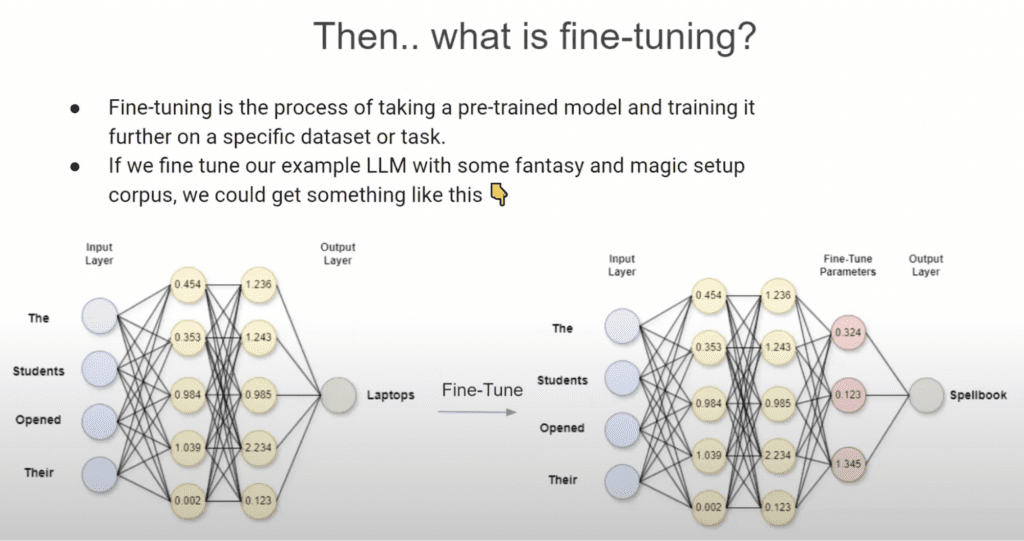
Let’s look again at the visual representation of an LLM that’s trained and compare it to one that’s fine tuned.
In the image above you can see that the trained model was able to take the input “The students opened their…” and come up with a relevant output: laptops.
When you add fine-tuned parameters to the model, you can make its output even more specific to your needs. In my example, I’ve made the model an expert in magic and fantasy.
The output now becomes: spellbook. That’s highly specific and relevant to my imagined needs—much more so than the output laptop.
Why would you need such customization of AI in your business?
Because it can give you more efficient operations, better customer experiences, and a stronger competitive position in your market.
It’s a method I love and one I would point any business leader toward because it’s the most efficient and most cost-effective way to get the most out of AI.
That’s why I’ve outlined how to fine-tune an LLM below. I encourage you to use it as a blueprint in your own business.
How to Fine-Tune an LLM | Real Example
Prefer to see it in action? 📽️ Watch the webinar here.
Or read on for step-by-step instructions using our real-life example.

Step 1: Define the Objective
What do you want your LLM to achieve that it can’t with its pre-existing training?
This step lays the foundation for all the others. Without it, you won’t know what dataset to use, what pre-trained model to select, or what you’ll fine-tune it to achieve.
For example, do you want the model to generate customer support responses, analyze legal documents, or create marketing content? The objective will guide the entire fine-tuning process.
In my example, I want my LLM to process dialogue and create a summary of what was discussed.
Step 2: Choose a Pre-trained Model
I’m using the Flan T5 which is already trained to handle conversation.

Common models include GPT-4, BERT, or T5, depending on the nature of the task (e.g., text generation, classification, summarization).
You can choose a pre-trained model from the Hugging Face repository.
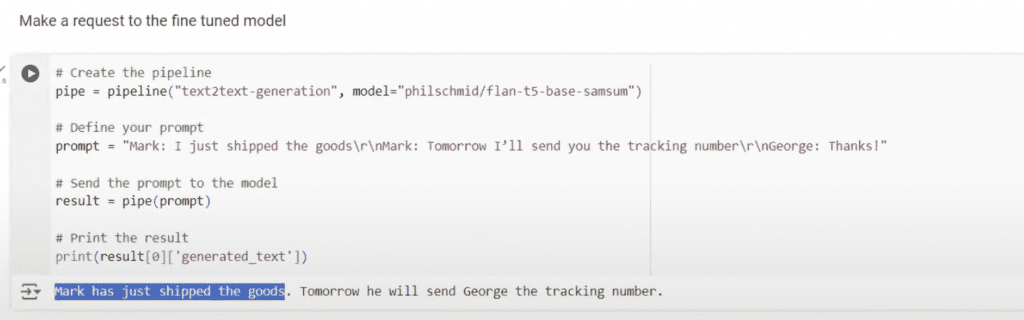
When I try to use my base model for my new task I get a pretty poor summary of the conversation.
Here’s what I put in:
And here’s what I get out of it:

Now, it doesn’t take a genius to understand that the summary is missing important context about what that tracking number is related to.
So we need a fine-tuned model to complete the task accurately. And to get that, we need a dataset to train it on.
Step 3: Set Up the Fine-Tuning Environment
To set up your environment you’ll need:
- Cloud infrastructure or commercial GPUs
- Access to the pre-trained model (which we took care of last step)
- A notebook environment to play around with code and fine-tune the model
I’m using a notebook service that’s popular for Python programming called Colab, where I can fine-tune the model using libraries like PyTorch.
My LLM requires substantial GPU support and I have a monthly subscription with Colab Pro that’s about $10. I’m essentially ‘renting’ the GPU capabilities from them. It’s a very affordable and very capable solution for my needs.
Step 4: Collect and Prepare the Training Data Set
The extensive datasets you use to train an LLM are often referred to as a “corpus,” which in Latin means “body.” Think of it as a large body of text that provides the raw material from which the model learns and the model retains.
Fine-tuning requires a new, task-specific corpus of training data that is human-made, ensuring it is diverse and high-quality.
Relying on AI-generated data could lead to inaccuracies, known as hallucinations, which might then negatively impact your model’s performance.
For my fine-tuning process, I’m using a SAMSum dataset consisting of thousands of dialogue examples, each paired with human-made summaries.
This ensures the model’s ability to understand and recognize patterns and generate coherent summaries based on actual human dialogue.
Before we can start, we need to tokenize the data from the dataset. Tokenization is the process of converting the text data into a format that the model can understand.
Instead of processing words directly, the model works with numbers. Each word or subword in the text is transformed into a numerical value or a vector embedding, which the model can then use to learn patterns and generate predictions.
Step 5: Fine-Tune the Model
To fine-tune the model, I’m using a technique called LoRA (Low-Rank Adaptation), which generates new parameters that we fine-tune to enhance the model’s ability to perform its specific task.
We’re actually only retraining about 16% of the model and that alone will specialize the LLM to our needs.
This is its fine-tuning in progress:
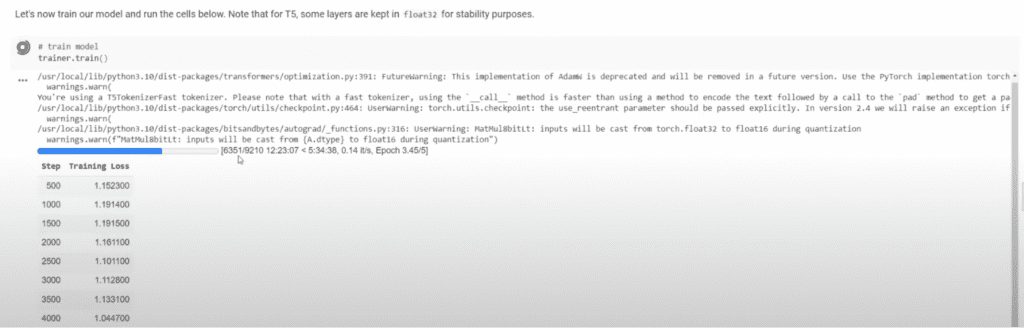
It will take about 17 hours using the consumer-grade GPU we have.
This approach is much more efficient than training a model from scratch, which would require an enormous amount of computational power—around 8100 GPUs for ten days, costing $1000s compared to the $10 dollars I’m currently spending.
Once complete, we can make requests and get more accurate outputs.
Inference AI—What, Why, and How?
When you interact with ChatGPT or any other AI-driven tool, you’re experiencing inference in action.
Inference is the process where the model takes everything it’s learned—both from its initial training (high school) and fine-tuning (university degree)—and applies that knowledge to generate responses or complete complex tasks itself.
If training is about acquiring knowledge, and fine-tuning is about specialization, then inference is about putting that knowledge to work in real-world scenarios.
Just like how you use what you’ve learned in school to excel in your job, an AI model uses an inference process to deliver the outputs you see. Whether it’s answering a question, generating content, or analyzing new data, inference is the phase where the AI “thinks” and produces results.
The speed and efficiency of inference have improved significantly over time.

For example, Groq, a company specializing in AI hardware, offers the fastest inference speeds and it will only get faster as the model learns. As we write this, it’s capable of 1000 tokens per second but at the pace AI training and inference are developing that could be exceeded as soon as we hit publish.
This means when you input a question or command, the response is generated almost instantly—far quicker than what you’d experience with traditional systems.
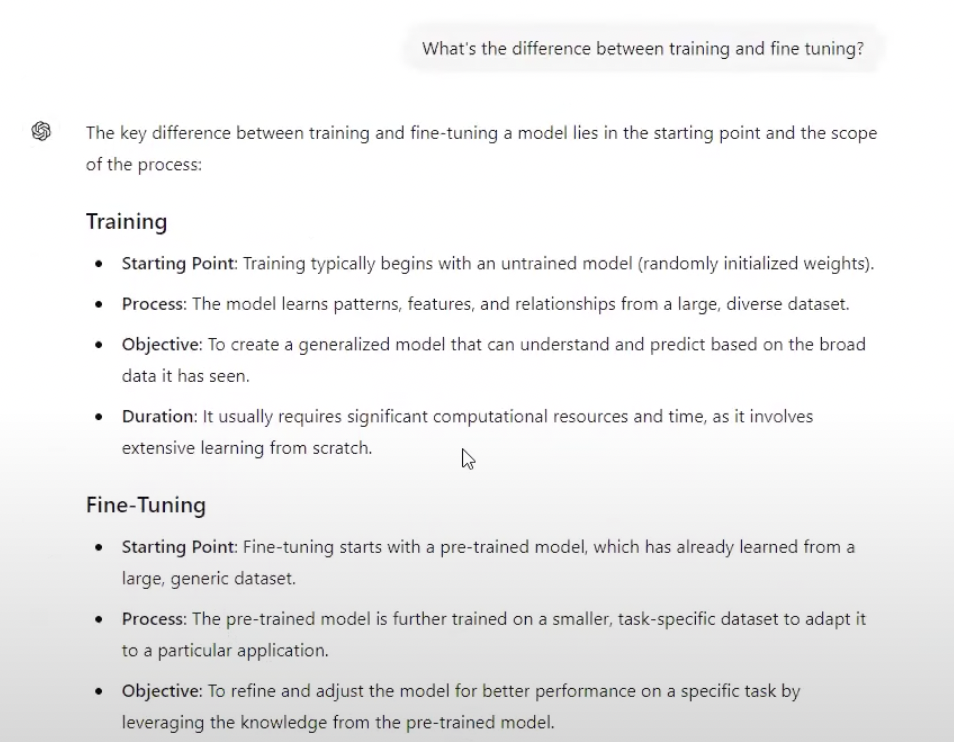
Try it for yourself. Head to ChatGPT and ask “What is the difference between training and fine-tuning?”
You get your answer pretty quickly, right? Faster than you would have been able to type it for sure.
It should look something like this:

This rapid inference speed is crucial for applications that require instant decision-making, like real-time data analysis or conversational AI in customer service.
Recently, ChatGPT moved to GPT-4.0, and this upgrade has also significantly improved inference speed.
Whether you’re generating a simple text or processing a complex query, the enhanced speed ensures a smoother, more efficient user experience.
Inference isn’t just about getting the right answer—it’s about getting it fast, and as AI continues to evolve, this speed will only get better, making tools like ChatGPT even more powerful and responsive.
Why Does Any of it Matter? A Summary
If you take anything away from this article, let it be this: fine-tuning is an affordable and powerful way to customize an LLM to meet your specific business needs.
By sourcing pre-trained models from repositories like Hugging Face and following the steps I’ve outlined, you can fine-tune it for a use case that gives your business a competitive edge.
AI is a great equalizer, but how you use it and the speed at which you adopt it will be what truly sets you apart from the competition.
Whether it’s enhancing customer experiences, streamlining operations, or driving innovation, the right AI strategy can propel your business forward in ways that were previously unimaginable.
And at HatchWorks AI we’re here to help you strategically leverage AI with these four solutions:
- An AI Roadmap and ROI Workshop that equips you with the knowledge to understand and apply AI to real-world use cases in your business.
- An AI Solution Accelerator program that takes you from idea to prototype to product faster. This approach provides a low-risk, high-value pathway for companies to validate and test AI technology on a small scale before committing to full production.
- Our RAG Accelerator will help you integrate any AI model and data source into your workflow. We tailor the service to you by safely and securely using your data to keep your AI up to date and relevant without spending time or money training (or fine-tuning) the model.
- AI-Powered Software Development—why build for yourself when we can do it for you in half the time?
Whether you’re just starting your AI journey or looking to refine your existing strategy and AI capabilities, our tailored solutions are designed to help you harness the full potential of AI.
Reach out to us today to schedule a consultation, and let’s explore how HatchWorks AI can accelerate and improve your business’s adoption of AI.
Talk to Our AI Experts
AI is transforming every business.
Make sure it transforms yours for the better.



