
Most automation tells a system exactly what to do: run these steps, in this order, every time. Goal automation is different. You hand an agent an objective, not a script, and it decides the steps for itself, adapting as it learns what the situation actually requires. This is the capability the rest of this series has been building toward, and it is also the one that demands the most discipline, because an agent that chooses its own path is only as safe as the boundaries you put around it.
This is the capstone of the harness cluster. It assumes the pieces already covered: Skills as the method, the agent harness as the runtime, and Claude Code and the Agent SDK as the ways to run it. Here we put them together and ask the real question of autonomy: how do you give an agent a goal and trust the result.

What this guide covers
From task automation to goal automation
There is a clean line between two kinds of agentic system. In one, a model and its tools are orchestrated through predefined paths: you have decided the steps in advance, and the system follows them. That is a workflow, and it is task automation. In the other, the model dynamically directs its own process and tool use, keeping control over how it reaches the outcome. That is an agent, and it is goal automation. The distinction is not which is better. It is that they fit different problems, and confusing them is how teams build an expensive agent to do a job a simple workflow would have done more reliably.
Goal automation earns its complexity when the steps cannot be known in advance. If a task is predictable enough to script, script it; a workflow is cheaper, faster, and easier to trust. Reach for an agent when the path is genuinely open-ended, when the work requires both reasoning and action, when there is a clear way to tell whether the goal was met, and when a human can meaningfully oversee the result. Those four conditions, an open path, real action, measurable success, and meaningful oversight, are the signature of work that is worth handing to an agent rather than a script.
The autonomy gradient
Autonomy is not a switch, it is a dial, and the safe way to use it is to start low and turn it up only as trust is earned. At every setting the agent does more and the human does less, and the right setting depends entirely on the cost of a mistake. Step through the levels to see what shifts at each one.
Choose an autonomy level
The agent
The human
Notice that nothing about the model changes across these levels. What changes is how much authority the harness grants it and where the human checkpoints sit. That is the whole game of goal automation: the same agent becomes an adviser, an assistant, or an operator depending entirely on the boundaries you set, which is why the boundaries deserve as much design as the goal itself.
What to automate first
Not every goal is a good first candidate, and choosing badly is the fastest way to lose trust in the whole approach. Two questions screen most candidates. First, what is the cost of an error, and how easily would you catch it? A mistake that is cheap to reverse and obvious when it happens is safe to automate aggressively; a mistake that is expensive and hard to detect is exactly where autonomy becomes a liability rather than a help. Second, can success be verified? If there is an objective signal that the goal was met, an agent can check its own work and you can trust the result. If success is a matter of taste or judgment, the agent can assist but should not decide.
This is why agentic coding took off before most other categories. The work is genuinely open-ended, the output has clear value, and a test suite gives an unambiguous verdict on whether the change worked. That combination, a reversible action with a reliable success check, is the profile of an ideal first goal. When you are choosing where to start, look for the same shape in your own work: a task with real ambiguity, a bounded blast radius, and a way to know for certain that it is done right.
The anatomy of a goal you can hand off
Once you have chosen a goal worth automating, it has to be specified well enough to delegate. A goal an agent can safely pursue has five parts, and a missing one is usually the reason an autonomous run goes wrong.
Part 1
A clear objective
What done looks like, stated so the agent and you would agree on it.
Part 2
A success check
An objective signal, like a passing test, that confirms the goal was met.
Part 3
Bounded authority
The tools and scope it may use, and the ones it may never touch.
Part 4
A stop condition
When to finish, and a turn limit so a confused run fails fast.
Part 5
A checkpoint rule
Which actions require a human before they happen.
Read those five parts back and you will recognize them from the harness. The objective and stop condition shape the loop, the success check is verification, the bounded authority is the permission layer, and the checkpoint rule is where a human enters it. A delegable goal is really just a harness configured with intent, which is the bridge from the runtime you learned to operate into the autonomous work you actually want.
Verification is what makes autonomy safe
The single thing that separates an agent you can trust from one you cannot is whether it can tell, on its own, that it is making progress. An autonomous agent works by getting ground truth from its environment at each step: the result of a tool call, the output of a command, the verdict of a test. That feedback is what lets it course-correct rather than drift confidently in the wrong direction. A goal with a strong, automatic success signal can be handed off with real autonomy, because the agent and the system can both see whether the work is right. A goal with no objective check cannot, no matter how capable the model is.
In practice you build verification in layers. The most powerful is an external check the agent cannot talk its way around: a test suite, a schema, a validator, a build that either passes or fails. Above that, an evaluator step can judge output against explicit criteria and send it back for another pass until it clears the bar. And above that sits the human checkpoint, reserved for the judgments no automated check can make. The more of this you can push down into automatic checks, the further you can safely turn up autonomy, which is the entire reason verification, not raw model capability, is the real ceiling on how much you can delegate.
HatchWorks AI is an Official Anthropic Claude Partner. Our Anthropic-certified Forward Deployed Engineers deploy Claude into your business and make it stick.
See how our FDEs work →How to invoke it: the /goal command
In Claude Code, goal automation is not a pattern you assemble by hand. It is a built-in command. You type /goal followed by the finish line you want, and Claude keeps working across turns on its own until that condition is met, with no re-prompting between steps. Setting the goal starts a turn immediately, with the condition itself as the instruction, and a live indicator shows how many turns, how much time, and how many tokens the run has used. If you do not see it, update Claude Code, since it arrived in a recent version.
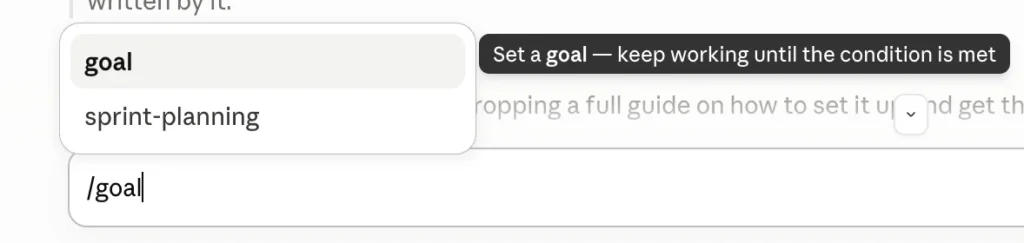
What makes this more than a keep-going loop is how completion is judged. After every turn, a separate, smaller model reads the conversation and answers one question: is the condition met. If it is not, that model's reason becomes the instruction for the next turn. If it is, the goal clears itself. Verification is built into the command.
You
Write a condition
Run /goal with the verifiable end state you want.
Claude
Works a turn
Reads, edits, and runs commands toward the goal.
Evaluator
Checks the transcript
A separate model decides whether the condition is met.
Loop or stop
Not met loops, met clears
Another turn starts, or the goal completes and hands back control.
Every principle from this guide shows up in how you write that one line. The evaluator only judges what Claude has actually shown in the conversation, so the condition has to be phrased around observable output, a test command that exits clean or a working tree with no changes, not an intention like improve the code. That is the success check from earlier, made literal. Adding a cap such as the stop after 20 turns clause is the stop condition, and it matters because there is no built-in token budget: without it, a goal the agent cannot satisfy will run until you interrupt it. And because setting a goal still respects your per-tool approvals, pairing it with auto mode is what lets each turn run unattended, which is exactly how you move up the autonomy gradient from running with checkpoints toward autonomous within bounds. Clear an active goal at any time with /goal clear.
The command is the Claude Code embodiment of everything in this article. When you build your own agent instead, you implement the same shape yourself, an evaluator or stop condition that decides whether to run another turn. Our guide to the Claude Agent SDK covers that build-your-own version of the same loop.
Putting the cluster to work
Goal automation is where every piece of this series comes together, because a working autonomous agent uses all of them at once. The pieces stack into one system.
Method
Skills
Codify how each part of the work is done correctly, every time.
Runtime
The harness
Runs the loop, manages context and memory, and enforces control.
Where it runs
Claude Code or the SDK
Drive it interactively, or embed it in your product or pipeline.
The orchestration
Goal automation
A goal, its success check, and its boundaries, sitting on top of it all.
Concretely: Skills supply the repeatable method the agent applies, the harness gives it the loop and the controls, and you deploy that through Claude Code for hands-on work or the Agent SDK for embedded and unattended work. Goal automation is the thin, decisive layer on top: the objective, the verification, and the human boundaries that turn all that capability into work you can actually trust to run on its own. The lower layers make autonomy possible. This layer makes it safe.
Where humans stay in the loop
The core tension of autonomy is simple to state: to be useful an agent must act on its own, but to be safe a human must keep meaningful control over how it acts. The way to hold both at once is to stop treating oversight as a single yes-or-no and instead sort decisions by who should own them. At HatchWorks, the GenDD Three-Tier Human and AI Boundary Model does exactly that, placing every decision in one of three tiers. Try sorting a few decisions below.
Who should own this decision?
The three tiers are the working vocabulary of the model. Agent-autonomous decisions are reversible and verifiable, so the agent acts and a human reviews after. Human-approved decisions are consequential or externally visible, so the agent prepares and a human signs off before anything happens. Human-owned decisions involve judgment or irreversible cost that no automated check can stand in for, so the agent can advise but never act. Drawing those lines explicitly, before an agent runs, is what lets you raise autonomy without losing control, and it is the difference between an agent that is trusted and one that is merely tolerated.
Common failure modes
Goal automation fails in recognizable ways, and almost all of them trace back to a missing boundary or a weak success check.
Without an objective signal that the goal was met, the agent cannot tell whether it succeeded and neither can you. It will report confident completion of work that is wrong. If you cannot define the success check, the goal is not ready for autonomy.
Granting full autonomy before an agent has earned trust on a task invites a costly surprise. Start at suggest or approve, watch where it goes wrong, and raise autonomy only as the failure rate proves it is safe.
Too many checkpoints cause approval fatigue and people rubber-stamp; too few let an irreversible action slip through unreviewed. Put human sign-off exactly where a mistake would be costly and hard to undo, and nowhere else.
A rule the agent is asked to follow can fail under pressure or a prompt injection. Anything that must never happen belongs in a hard deny rule or a hook, enforced by code, not in a prompt the model is trusted to obey.
An autonomous agent that gets stuck will keep working until something stops it. A turn limit and a spend ceiling turn a runaway loop into a fast, cheap failure you can inspect rather than an expensive one you discover later.
From goal automation to a methodology
Everything in this series points to the same conclusion. The model is remarkable, the harness is capable, and the tools are powerful, but none of that decides whether autonomous work can be trusted. What decides it is discipline: choosing the right goals, specifying them with a success check and clear boundaries, building verification in layers, and drawing the human and AI line before the agent runs rather than after it goes wrong. Capability is necessary. It is not sufficient.
That discipline is what a methodology is for, and it is why every article in this cluster has ended in the same place. At HatchWorks, Generative-Driven Development turns these practices into a repeatable system: Skills codify method, the harness runs it, the GenDD Execution Loop wraps the agent loop in planning and verification, and the Three-Tier Human and AI Boundary Model keeps people in control of the decisions that matter. Goal automation is the payoff the whole series was building toward, and a methodology is what turns it from an impressive demo into work your organization can depend on. That is the work we do with engineering teams every day.
You've seen what it takes to hand an agent a goal and trust the result. An FDE draws the autonomy and human boundaries inside your business so goal automation is safe to run for real.
Official Anthropic Claude Partner
Part of the Claude Partner Network, HatchWorks AI embeds Anthropic-certified Forward Deployed Engineers in your team to find where Claude delivers value, ship it into production, and help make adoption stick.
Talk to a Forward Deployed Engineer See how FDEs work


