
This article breaks down the exact process I’ve used to select, modify, and apply small language models to dozens of use cases in my work.
Take it, make it yours (or share it with those in your company who can), and put your business on the fast track to innovation.

👋Hi, I’m David Berrio, Senior ML/AI engineer here at HatchWorks AI. I’m obsessed with all things AI and language models, spending much of my time learning how to leverage them to improve client software projects, our own processes at Hatchworks AI, and my personal hobbies.
Short on time? Get the highlights with these four key takeaways:
- In the SLM vs LLM debate it’s not a matter of either or, it’s a matter of which one when. Both have valuable uses but SLMs stand out for cost and task precision.
- Structuring an SLM to your use case is easier than you think. My favorite way to do it is by combining two methods: Knowledge distillation of a larger model and fine-tuning with a LoRa approach.
- Your small language model will require a set of defined and highly specific prompts that can’t be edited by just anyone.
- When your SLM is up and running for your specific use case, make sure to maintain it and update it with new data as it becomes available.
Watch the full webinar:
This article is based on my 1-hour long webinar on the same topic where I walk you through two use cases for small language models and cover the basics of small language model adoption.
📽️ Watch it here.
What Are Small Language Models? And How Are They Different From Large Language Models?
A small language model, or SLM, is a streamlined, smaller, and simpler alternative to large language models (LLMs).
While both are able to process and generate human language, an SLM has a more compact architecture, works from fewer parameters, and requires less computational power and training data.
And while training an LLM can take days or even months, training an SLM can be significantly faster.
This faster training process allows for more rapid iteration and customization of SLMs for specific tasks or domains, making them ideal for businesses.
But what does ‘small’ really mean? It’s relative, really. Only a few months ago, small language models would have been considered large ones.
So for clarity’s sake, when I talk about an SLM I mean any model that’s trained on up to 1 billion parameters.

This shift represents how quickly our perception of language models has changed alongside rapid advancements in technology.
📚If that’s a topic you want to explore further, check out our two pieces:
- Large Language Models: Capabilities, Advancements, and Limitations [2024]
- Embrace Generative AI in 2024: A Detailed Guide for Seamless Team Integration
When comparing LLMs and SLMs, it’s helpful to think of them in terms of cars. LLMs are like Ferraris—powerful, impressive, and capable of handling complex tasks, but also expensive and resource-intensive.
Capable small language models, on the other hand, are like Honda Civics—reliable, efficient, and accessible. They get the job done without breaking the bank. And that’s something any business can get behind.
Plus there’s no need to have a flashy model when all the good stuff is kept under the hood and no one will know what you’re operating with.

| LLM (large language model) | SLM (small language model) | |
|---|---|---|
|
Training
|
Trained on billions of parameters
Training process can take weeks or months
|
Trained on up to 1 billion parameters
Training process can be completed in a relatively short time
|
|
Resource requirements
|
Computationally intensive, requiring significant resources
|
Computationally efficient, requiring fewer resources
|
|
Capabilities
|
Excels at handling complex, large-scale tasks
Can generate human-like text across a wide range of domains
|
Performs well on targeted, domain-specific tasks
Can generate high-quality text within specific contexts
|
|
Customization
|
More challenging to fine-tune for specific applications
|
Easier to fine-tune and customize for specific applications
|
|
Ease of deployment
|
Deployment can be resource-intensive and costly
|
Deployment is more efficient and cost-effective
|
Step-by-Step: How to Use Small Language Models for Industry-Specific Use Cases
In the HatchWorks AI Lab I ran on this same topic, I demonstrated how to use small language models through two examples:
- A company looking to enhance its financial oversight and expense tracking faces the daunting task of processing hundreds of receipt documents daily.
- A courier company that wants to ensure the integrity of packages throughout their distribution process.
I’m going to reference those same use cases in this article and break down the process step-by-step, but keep in mind that these steps can be applied to more than the examples I provide. Get creative in your own application!
Before I go into each step, let’s look at the two use cases in a little more detail:
Case 1: Enhancing Financial Oversight and Expense Tracking
In this scenario, a company is looking to streamline its financial oversight and expense tracking processes. The main challenge lies in processing hundreds of receipt documents daily, each with its unique layout and structure. Extracting crucial information such as vendor names, dates, amounts, and item descriptions from these diverse receipts can be a daunting and time-consuming task.
This use case is particularly relevant for companies dealing with large volumes of documents involved in internal processes that are manual and difficult to extract information from. By leveraging SLMs, the company aims to automate the extraction of key details from receipts, saving time and reducing the risk of human error.
Case 2: Ensuring Package Integrity in Courier Services
In this use case, a courier company aims to maintain the integrity of packages throughout their distribution process. As packages move through various stages, it’s essential to ensure they remain in good condition. To monitor this, company operators capture photographs of each package at every step of the distribution chain.
The goal is to use an AI model designed to compare these images over time to detect any potential damages that may occur during the distribution process. By analyzing the images captured at different stages, the model can help identify which steps in the process are more likely to cause damage to packages.
Unlike the first use case, which focuses on text-based data analysis, this scenario involves using computer vision techniques rather than chat-based AI. The AI model will need to be trained to recognize and compare visual patterns in the package images to detect any anomalies or signs of damage.
Step 1: Determine if a Small Language Model is Better than an LLM
Before you begin, you need to determine if a small language model or a large language model is the better fit.
And before you do that, you need to identify your use case—what it is you want the language model to do for you.
In the use cases I’ve presented, LLMs like ChatGPT-4, Gemini, Claude 3, Grok, or Le Chat Mistral Large could work. But I don’t need a model with 300 billion parameters to answer the same question over and over again—which is all that’s needed to complete the tasks.
You need to come to your own conclusion. To do so, ask yourselves these four questions:
Question 1: What is the complexity of the tasks the model needs to perform?
If the tasks involve understanding nuanced context, generating detailed responses, or handling a wide range of topics, an LLM might be necessary.
For simpler, more repetitive tasks, such as extracting specific information from structured documents or comparing images for anomalies, an SLM could be a better option.
Question 2: What are the computational resource constraints (e.g., CPU, GPU, memory)?
If your project has limited resources, such as when computing on the edge or on mobile devices with restricted capabilities, an SLM might be more practical and efficient.
Question 3: Are there strict privacy or security requirements?
If the application involves sensitive data, such as financial information or personal details, the additional scrutiny and potential compliance issues with using a large-scale model should be considered.
SLMs, being smaller and more focused, might be easier to audit and secure, providing greater control over data privacy and data security.
Question 4: How frequently will the model need to be updated or retrained?
LLMs might require more effort and resources to retrain and update due to their size and complexity.
If frequent updates are expected, an SLM might be a good option if other requirements are met, as they’re generally easier and faster to retrain.
Step 2: Structure your SLM (it’s easier than you think!)
Now that you know a small language model is the best fit for your industry use case, you need to structure the SLM.
You have four options when doing this:
1. Use a pre-trained SLM (such as those found in Hugging Face)
There are already pre-trained SLMs available on platforms like Hugging Face that cater to various use cases.
If you find an SLM that aligns with your specific requirements, you can leverage it directly without the need for extensive training or fine-tuning.
This option saves time and resources, especially if you have a common use case that doesn’t require highly specialized knowledge.
2. Train a model from scratch
If your use case is highly specific or requires unique domain knowledge, you may need to train an SLM from scratch.
This involves collecting and preprocessing relevant data, designing the model architecture, and training the model using the prepared data. Training from scratch gives you complete control over the model’s performance and allows you to tailor it precisely to your needs.
However, it also requires more time, resources, and expertise compared to using a pre-trained model.
3. Perform knowledge distillation from small models to a bigger model
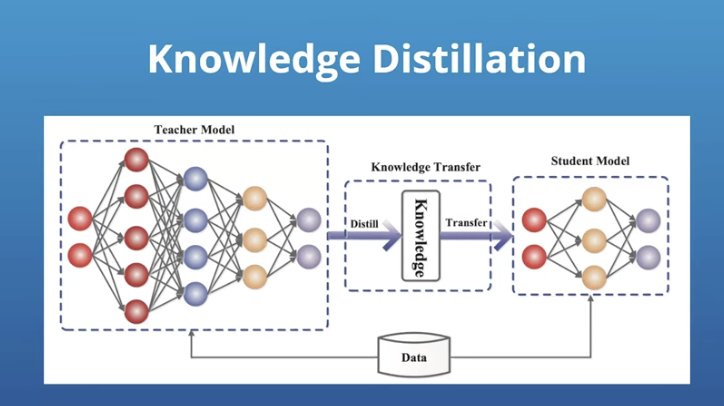
Knowledge distillation is a technique that involves transferring knowledge from a larger, more complex model (like an LLM) to a smaller, more compact model (an SLM).
This process helps create a smaller model that retains much of the knowledge and capabilities of the larger model while being more efficient and easier to deploy.
Knowledge distillation can be an effective way to create an SLM that benefits from the insights and performance of an LLM without the associated computational costs and resource requirements.
4. Take an already trained model and fine-tune it
Fine-tuning involves training a pre-existing model (either a pre-trained SLM or a model obtained through knowledge distillation) on a smaller, more specific dataset relevant to your use case.
This process adapts the model to your particular domain or task, improving its accuracy and reducing the likelihood of hallucinations (i.e., generating irrelevant or incorrect outputs).
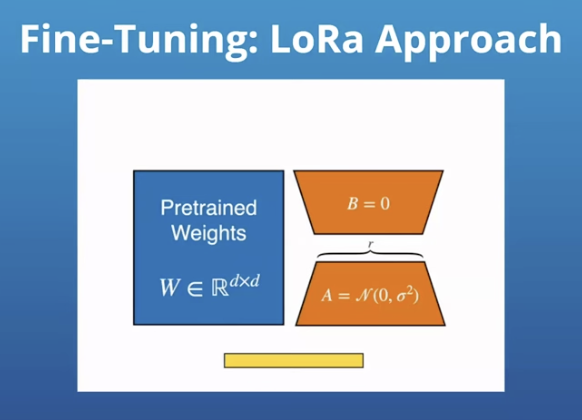
Fine-tuning allows you to leverage the general knowledge of the pre-existing model while tailoring it to your specific needs, resulting in better performance and more reliable outputs.
You’re not going to finetune the whole model but just a few bits of it. This is a popular approach because it doesn’t require much infrastructure or time.
What I typically do:
I like to combine options 3 and 4 because knowledge distillation makes it smaller while fine tuning makes it more accurate and tailored to your use case. Then you can save money and get fewer hallucinations from the model.
You can go to Hugging Face’s repository of LLMs to find one, distill it, and fine-tune it to your unique needs.
Let’s look at how I structured my SLM for the first use case I introduced earlier:
Step 3: Create defined prompts for the SLM to follow
Well-defined prompts serve as the foundation for the SLM’s responses and guide the model towards generating relevant and accurate outputs. For most industry use cases, where you’re automating a task, you’ll need a fixed prompt.
Fixed prompts are predefined and cannot be edited by users. They ensure consistency and reliability in the SLM’s responses, as the model is trained to respond to specific patterns and structures.
Fixed prompts can be standalone, focusing on a single task or question, or they can be compounding, building upon previous prompts to generate more complex or detailed outputs.
Below, I’ve outlined some examples of fixed prompts based on the use cases we’ve discussed:
Fixed Prompts for Case 1: Enhancing Financial Oversight and Expense Tracking
In this scenario, we need a set of fixed prompts that are predefined in the backend of the application and not open to external users. These prompts will guide the SLM in extracting specific information from receipts and financial documents. Some examples of fixed prompts for this use case include:
- What is the purchase amount?
- Who is the seller?
- Who is the buyer?
- How much tax was paid?
By using these fixed prompts, the SLM can consistently extract the relevant information from the receipts, enabling the automation of expense tracking and financial oversight processes.
Fixed Prompts for Case 2: Ensuring Package Integrity in Courier Services
For the courier service use case, we again need a fixed set of prompts. In this scenario, the primary focus is on comparing images of packages at different stages of the distribution process to identify any potential damage or changes in their physical integrity. A key fixed prompt for this use case could be:
What is the physical state of the box? Compare the pictures provided and determine if the package in both images is the same and spot any notable differences in their physical integrity.
This prompt directs the SLM to analyze the provided images, compare the physical state of the package at different points in time, and identify any discrepancies or signs of damage. By using this fixed prompt, the SLM can consistently evaluate the condition of packages throughout the distribution process, enabling the courier company to monitor and ensure the integrity of their deliveries.
- Be specific and clear: Ensure that your prompts are well-defined and unambiguous, leaving no room for misinterpretation.
- Cover all necessary aspects: Include prompts that cover all the essential information or tasks required for your use case.
- Use consistent formatting: Maintain a consistent structure and formatting across your prompts to make it easier for the SLM to understand and respond accurately.
- Test and refine: Iterate on your prompts based on the SLM’s responses, refining them to improve the model’s performance and accuracy.
Step 4: Send those prompts to the model
Next, you need to integrate these prompts into your application. And that involves a few key steps:
1. Preprocessing
Before sending the prompts to the SLM, you may need to preprocess the input data. In the case of receipts or financial documents (Case 1), this involves converting the image into a format that the SLM can understand.
For most SLMs, this means converting the image to a vector representation. Fortunately, many SLMs have this preprocessing step built into their first layer, so you may not need to handle this conversion explicitly.
If your SLM doesn’t have built-in preprocessing layers to handle this conversion, you may need to use techniques like feature extraction or embedding to convert the raw input data into a suitable vector representation.
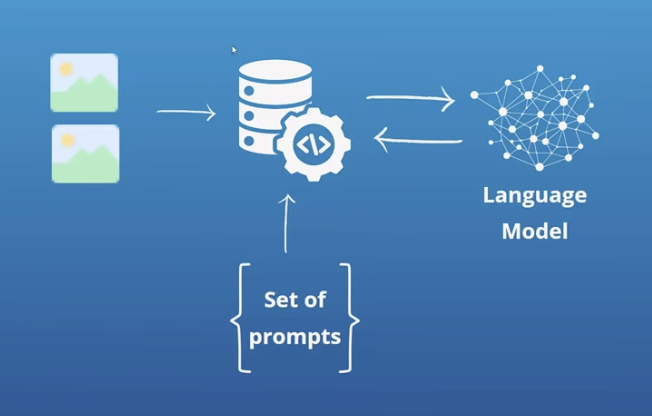
2. Prompt integration
Integrate the fixed prompts into your application’s backend. This involves setting up the necessary infrastructure to send the prompts along with the preprocessed input data to the SLM.
In the receipt example, you would send the receipt image along with the predefined prompts (e.g., “What is the purchase amount?”, “Who is the seller?”) to the SLM.
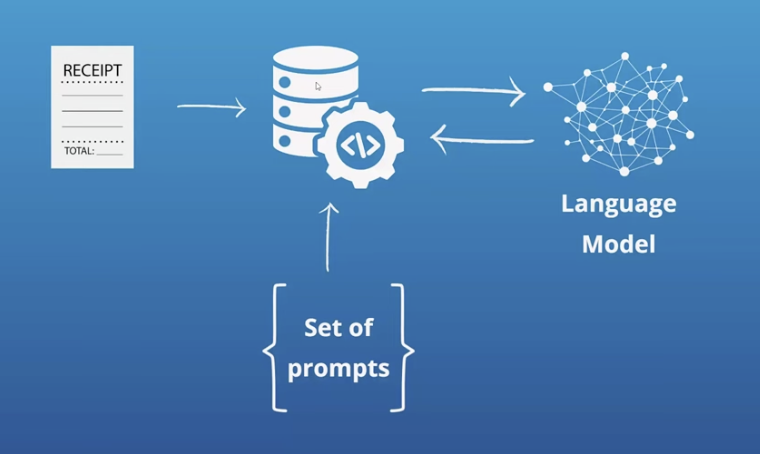
3. Model inference
Once the prompts and input data are sent to the SLM, the model performs inference to generate the desired outputs.
During this process, the SLM uses its trained knowledge to analyze the input data and provide answers or results based on specialized data and on the given prompts.
In the case of the receipt example, the SLM would extract the relevant information from the receipt image based on the prompts and return the answers.
4. Post-processing
After obtaining the results from the SLM, you may need to post-process the outputs to ensure they are in the desired format or structure. This could involve parsing the SLM’s responses, extracting specific pieces of information, or formatting the results for display or storage.
Step 5: Deployment and Integration Into Your Systems
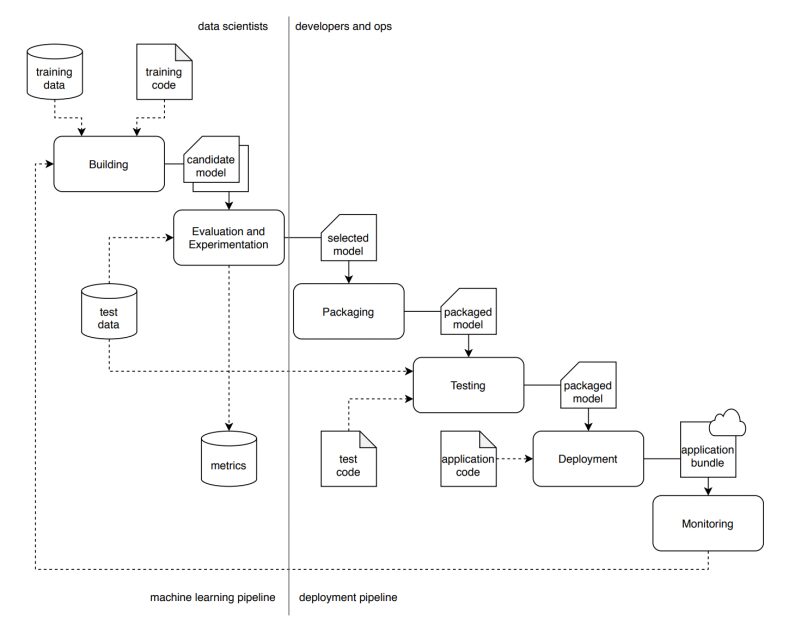
Next you need to deploy and integrate your small language model into your existing systems.
This often involves containerizing your SLM using technologies like Docker or Kubernetes, developing an API to expose its functionality, and integrating it with your current workflows.
In my expense tracking use case, the SLM would be integrated into the expense management system, automatically processing receipts and extracting relevant information.
For the courier service scenario, the SLM would be integrated into the package tracking system, assessing package integrity at each stage of the delivery process.
Step 6: Monitor and Maintain
Once deployed, you want to keep your SLM in working order which means establishing processes for monitoring its performance and maintaining it over time.
This involves tracking key metrics, high quality data such as accuracy and response times, and promptly addressing any issues that arise.
I recommend setting up automated alerts to notify you of significant deviations in the model’s performance or unexpected behavior.
You also want to regularly update the model by incorporating new data and improvements as it becomes available and as the business changes. This helps maintain the model’s relevance and effectiveness in your specific niche.
Key Considerations When Using Small Language Models in Business
If you’re going to use an SLM in any aspect of your business, there are a few considerations you should make. I’ve broken them down into three categories with a checklist you can run through to make sure you’re considering them effectively.
Technical Requirements and Scalability
Here, you want to make sure your infrastructure can support the SLM and handle future growth.
✅Assess infrastructure compatibility with SLM deployment and operation
✅Evaluate expected workload and plan for scalability
✅Ensure compatibility with existing systems and technologies
Cost Implications and Optimization Techniques
While SLMs are generally more cost-effective than large language models (LLMs), it’s important to optimize their usage to minimize expenses.
✅Define a clear and specific set of tasks for the SLM (keep in mind that SLM tasks need to be more defined compared to LLMs)
✅Continuously monitor and analyze SLM usage patterns
✅Implement cost-saving measures (e.g., efficient data processing, caching, resource allocation)
✅Optimize SLM usage to minimize unnecessary processing and reduce costs
Ensuring Model Efficiency and Performance
Small language models are meant to reduce workload and increase efficiency. If it doesn’t, you’ll need to decide if there’s a way to fix it or if you need another solution.
✅Fine-tune and update the model periodically
✅Incorporate user feedback and new data for continuous improvement
✅Implement error handling and logging mechanisms
Other Industry Use Cases Perfect for Small Language Models
SLM use cases aren’t confined to the two examples I used in this piece and in the webinar.
So if you didn’t identify with those and are wondering if there’s a way for you to benefit, rest assured, there is.
Below, I’ve listed a few industry use cases I think are perfect for small language model use.
Healthcare:
- Patient Data Entry and Management: Assist in the automated entry of patient data into electronic health records (EHRs) from dictated notes or forms, reducing clerical workload.
- Preliminary Diagnostic Support: Analyze patient symptoms and medical history to provide preliminary diagnostic suggestions or flag potential issues for further review by healthcare professionals.
Finance:
- Fraud Detection: Monitor transactions for unusual patterns and alert human analysts to potential fraudulent activity.
- Automating Routine Financial Reporting: Generate standard financial reports, summaries, and dashboards by processing transactional data and financial records.
Retail:
- Personalizing Customer Recommendations: Analyze customer purchase history and browsing behavior to suggest products that align with their preferences and buying patterns.
- Inventory Management Assistance: Help predict stock requirements and optimize inventory levels by analyzing sales trends and seasonal demand.
Legal:
- Document Drafting and Review: Assist in drafting standard legal documents and contracts by filling in templates based on user inputs and legal guidelines.
- Summarizing Legal Texts and Case Law: Provide concise summaries of lengthy legal documents, case laws, and judgments to help legal professionals quickly understand the key points.
Human Resources:
- Resume Screening: Automatically screen and rank resumes based on predefined criteria, helping HR teams to shortlist candidates more efficiently.
- Answering Employee Queries About Company Policies: Provide instant responses to employee questions regarding benefits, leave policies, and other HR-related queries.
Manufacturing:
- Monitoring Production Lines: Assist in real-time monitoring of production lines to identify bottlenecks, ensure quality control, and suggest adjustments.
- Predictive Maintenance: Analyze data from machinery and equipment to predict when maintenance is needed, preventing breakdowns and reducing downtime.
Agriculture:
- Crop Disease Detection: Analyze text and image data from farmers to identify potential crop diseases and suggest treatments.
- Optimized Planting Schedules: Provide tailored advice on planting schedules and crop rotation based on local weather forecasts and soil conditions.
Treat these as inspiration for your own use and if you’re still left wondering how you can use and scale small language models in your business, get in touch. I’ll be happy to field some questions to get you on track.
📚You may also like: LLM Use Cases: One Large Language Model vs Multiple Models
FAQs on Small Language Models
What is a small language model?
A small language model (SLM) is an AI model designed to process and generate human language, with a compact architecture, fewer parameters, and lower computational requirements compared to large language models (LLMs).
What is an SLM vs a Large Language Model (LLM)?
Small language models and large language models differ primarily in their size, complexity, and computational requirements. Small language models are smaller, faster, and more cost-effective, making them suitable for specific tasks and resource-constrained environments. Large language models, on the other hand, are larger, more powerful, and can handle a broader range of complex tasks.
What are the benefits of small language models?
Small language models offer several benefits, including:
- faster training times
- lower computational requirements
- cost-effectiveness
- easier deployment on edge devices
- better customization for specific domains or tasks
They also provide improved privacy and security due to their smaller size and reduced data requirements.
What are the use cases of small language models?
Small language models are suitable for various applications, such as chatbots, content moderation, sentiment analysis, named entity recognition, text summarization, and domain-specific tasks like invoice processing or customer support.
They are particularly useful when computational resources are limited, or when tailored, efficient models are needed.
What is the future of small language models?
Personally, I think small language models are going to become more and more popular as businesses learn how to customize them to their own processes and use cases. And AI is only getting smarter, better, and faster so I expect the size of small language models and LLMs to grow and for their capabilities to become more enhanced.
What are examples of small language models?
Some examples of small language models include DistilBERT, TinyBERT, MobileBERT, and ALBERT. These smaller models are derived from larger models like BERT but have been optimized for efficiency and reduced resource requirements while maintaining comparable performance on various natural language processing tasks.
David Berrio is a seasoned professional in AI and Data Science with extensive expertise in developing and deploying ML algorithms, leveraging a strong command of MLOps and Microservices. His career features significant experience in Computer Vision, Machine Learning, Azure Cloud, and state-of-the-art Deep Learning Architectures. A lifelong learner, David is always at the forefront of technology. He believes in the power of knowledge to drive innovation and deliver impactful solutions, guiding his professional endeavors.

Let’s Build Your AI Strategy
Meet with our AI experts to explore your goals and challenges.
We’ll work with you to create a tailored AI Strategy and Roadmap that turns AI into ROI.



