
Power LLMs with Your Data
Sometimes it feels like we’re all in a race to effectively and affordably adopt AI. Only there are hurdles in the way.
Like how Large language models, despite their impressive capabilities in natural language processing, trip you up when it comes to hallucinations and inaccuracy. These are more than an inconvenience, they’re a liability that could lead to poor decision-making, financial costs, and a loss of customer trust.
Applying Retrieval Augmented Generation (RAG) to an Large Language Model (LLM) can help you enhance AI capabilities and minimize the risk. By anchoring AI responses in your own current, relevant data, retrieval augmented generation evolves a model’s outdated, opaque outputs into real-time, auditable insights.
In this article, we explain how you can use retrieval augmented generation to create memorable, differentiated experiences for your end-users without needing to exhaust a well of resources fine-tuning off-the-shelf models.
We also introduce our RAG Accelerator, which helps you soar over the hurdles of AI adoption and reach the finish line faster than your competitors.
Here’s what you stand to gain:
Democratize insights for all
Talk to your data in real-time
Prevent AI hallucinations
Create personalized experiences
Secure your data
Maintain control of your proprietary data, ensuring privacy and security without third-party exposure.
Reduce the cost of AI
Getting to Grips with RAG (Retrieval Augmented Generation) Architecture
I like to think of Retrieval Augmented Generation (RAG) as giving your language model a library it can source information from.
‘Books’ can be added to enhance the capabilities and accuracy of the model—only those ‘books’ are your structured and unstructured data. That data can be based on an internal data source or external data sources.
Here are some examples of structured and unstructured data:
| Structured data | Unstructured data |
|---|---|
|
|
Without the library, the LLM can only access ‘knowledge’ it’s already acquired—its training data. And unfortunately, that knowledge can become limiting and outdated.
Why? Because it can only access data from the internet, the same data everyone else has access to. Whereas retrieval augmented generation taps into your proprietary data in real-time.
Did you know?
You can build-in access control into your RAG system. That means your intern won’t have the same access to data as your CEO and your consultants only see what you want them to see.
This is also a great feature when applying RAG to your customer-facing digital products.
At HatchWorks AI we build that into our RAG Accelerator. You can learn more about that here.
It’s a no-brainer that you want your LLM to have a library filled with up-to-date information. Especially if you want to focus on knowledge-intensive tasks and make your data your differentiator.
The question is, how does that library get ‘built’? Let’s look at the RAG architecture to find out.
Retrieval Augmented Generation (RAG) architecture has three key stages: indexing, retrieval, and generation.
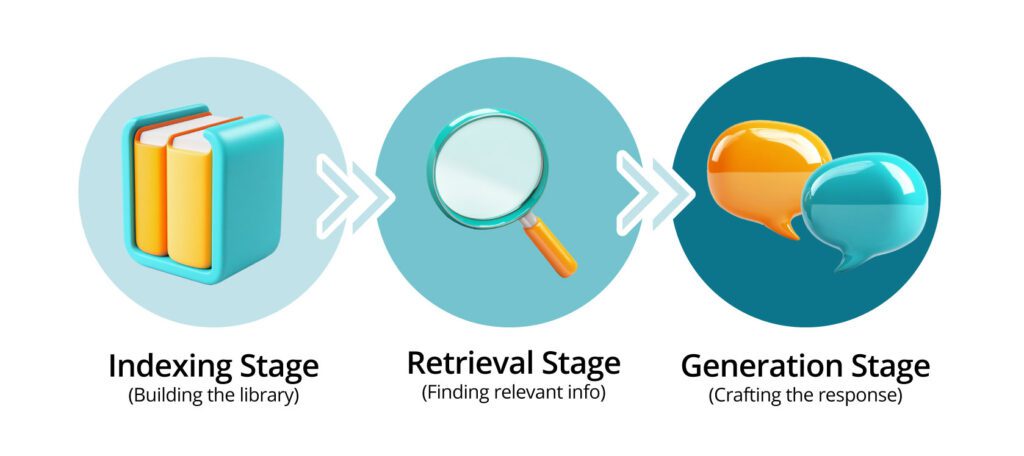
Each plays a crucial role, and together, they create some impressive AI capabilities. But keep in mind, the quality of your data and how you organize it can make or break that performance.
Let’s look at each stage to see how it all comes together.
📚But first, here are some LLM resources you might like:
The Indexing Stage
First up, indexing. This is where we fill the shelves of our AI’s library. It’s like cataloging a vast collection of books, ensuring each piece of information is easily accessible when needed.
The key here is to be thorough and accurate. Missing important info is like having gaps in your library catalog—it leads to incomplete knowledge and potentially inaccurate outputs. Tools like Elasticsearch or Pinecone act as your expert librarians, helping you organize this wealth of information efficiently.
The Retrieval Stage
Next, we’ve got information retrieval component. If indexing stocks the library, retrieval is about finding the right books when they’re needed. It’s as if your AI has a helpful librarian, ready to pull the most relevant information at a moment’s notice.
The quality of your retrieval mechanisms impacts your RAG system’s performance. It doesn’t just need to find relevant information—it needs to find the most pertinent details for the task at hand.
Fine-tuning these mechanisms is important because it’s the difference between your AI providing precise, useful information or getting lost in a sea of tangentially related facts.
The Generation Stage
Finally, we reach the generation stage. This is where your LLM acts as an author, using the retrieved information to write a compelling response to new data.
And the final response will only be quality if it strikes a balance between retrieval and generation.
Your AI needs to effectively use the information from its ‘library’ without simply reciting facts. It’s about synthesizing this knowledge into coherent, contextual, and engaging outputs.
By optimizing the interplay between the retrieval process and generation, you create AI responses that aren’t just knowledgeable, but also natural and relevant.
How to Set Up a Baseline RAG System with LLMs: Step by Step
Setting up a basic RAG system using Large Language Models might seem daunting at first, but with a systematic approach, it’s quite manageable. There are 4 steps we’ll follow.
They’ll give you a solid foundation for implementing RAG into your AI projects.
Want to save yourself the time and hassle of setting up RAG yourself or getting your team to do it?
At HatchWorks AI we’ve built a service around implementing RAG into a company’s AI solutions. It helps them leverage their biggest differentiator—their own data.
Learn more about our RAG Accelerator here or get in touch today to explore your options.
1. Prepare All Relevant Documents in the Knowledge Base
The first step is to create a comprehensive knowledge base for your RAG system.
You can begin hybrid search by collecting your data, both structured and unstructured. These can include articles, PDFs, web pages, or any relevant text data for your use case. Remember it can be internal knowledge (your proprietary company data) or external knowledge (like a public medical journal).
Since AI models process numerical data, you’ll need to transform these documents into numerical representations called embeddings.
To do this, select an embedding model appropriate for your domain. For general purposes, models like Sentence-BERT are effective, but for specific industries or applications, consider domain-adapted models that capture nuanced semantics better.
Once you’ve generated embeddings, store them in a vector database or indexing service.
Examples of Vector Databases Used in RAG:
- Pinecone: Cloud-native vector database optimized for machine learning and AI applications.
- Faiss (Facebook AI Similarity Search): A library for efficient similarity search and clustering of dense vectors.
- Weaviate: An open-source vector database that allows for combining vector search with structured data.
- Milvus: An open-source vector database built for scalable similarity search and AI applications.
These tools are optimized for fast similarity searches, which is crucial for efficient retrieval.
Just keep in mind the following:
- Data Quality: Ensure your knowledge base is clean, relevant, and up-to-date. Removing irrelevant sections or splitting longer documents into smaller chunks can improve retrieval granularity.
- Storage Strategy: Choose a vector storage solution that balances speed and capacity. For large-scale applications, consider using a distributed architecture or sharding techniques to manage the database effectively.
Expert tip:
To save hassle down the road, invest in a Vector Store that boasts features for metadata cataloging, governance, and observability. Databricks’s Mosaic AI Vector Search solution does just that, offering first-class integrations into the entire product suite.
Want to learn more? As a Databricks partner, we’re happy to talk!
2. Implement the Retriever to Find Relevant Information
With your knowledge base set up, the next step is to implement the retriever, which efficiently searches through the stored embeddings to find the most relevant source documents.
Begin by selecting a vector search engine; FAISS and Elasticsearch are popular choices, but Pinecone is also effective, especially for cloud-based deployments.
Set up the chosen search engine and index the document embeddings you created in the previous step.
Develop a retrieval function that converts a user query into an embedding and identifies the most relevant documents based on this embedding.
To enhance your retriever:
- Use Approximate Nearest Neighbor (ANN) Algorithms: These algorithms, used by tools like FAISS, speed up the search process by finding approximate matches, which is generally sufficient for most applications.
- Consider Hybrid Retrieval: Combine dense (vector-based) retrieval with sparse (keyword search) retrieval techniques to cover a broader range of potential queries and improve robustness.
- Fine-Tune Retrieval Settings: Adjust parameters such as the number of documents (K) retrieved per query to balance between relevance and diversity.
- Incorporate Metadata: Supplement your data with additional information about where it came from, what it applies to, when it was uploaded, and more.
3. Integrate with the LLM With Your Training Data
This is where we connect our retriever to the LLM, enabling it to generate responses based on the information in the data store. To return to the library metaphor, there is a choice here. You can either give the LLM a few books or, more powerfully, equip it with a library catalog for it to tell you exactly what books it needs.
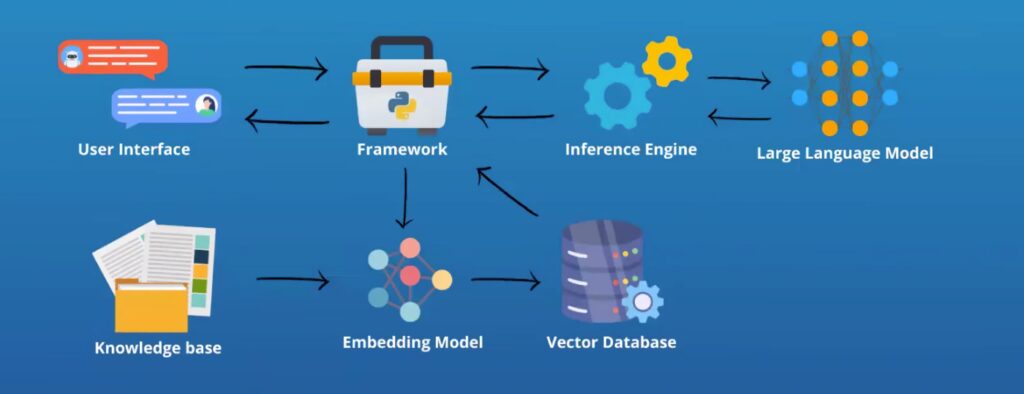
Whether based directly on the user’s query or on the LLM’s coaching, the documents you fetch from your training data store can be used to ground your bespoke response.
Combine these inputs into a single, enriched context, providing the LLM with both relevant results to the query and relevant background information.
Pay attention to how you format this input, as the structure can significantly impact output quality. For instance, using bullet points, summaries, or a Q&A format may help the LLM understand the context better.
Expert tip:
The success of your models will depend heavily on your prompts. It’s common wisdom that 80% of the complexity of AI products is in Prompt Engineering – the process of optimizing the performance of your system by tweaking the instructions given to the LLM.
Check out our Expert’s Guide: Generative AI Prompts for Maximum Efficiency for more.
Next, use your chosen LLM’s API (like GPT-3, GPT-4, Llama, Claude, Mistral, or any other suitable model) to generate a response based on this enriched context.
Keep these considerations in mind:
- Prompt Engineering: Carefully construct the prompt to include the right amount of information. Too much context might confuse the model, while too little might lead to less accurate responses.
- Optimize the Input Length: Since LLMs have a maximum input length, ensure you’re providing the most relevant context within these constraints.
If you’re not sure what LLM to use, check out the Hugging Face repository which helps you filter through LLM capabilities to source the right one for your needs.
📚Read our article where we teach you how to deploy an LLM on your own machine using RAG: How to Deploy an LLM: More Control, Better Outputs.
Learn better by watching? Check out the webinar that covers the same topic.
4. Deploy and Optimize
Now it’s time to get our RAG system up and running and then refine its performance.
Deploy your retriever and generator in an environment that fits your needs, whether cloud-based or on-premises. Once deployed, focus on optimization.
Experiment with different hyperparameters, such as adjusting the number of documents (K) your retriever pulls or testing different embedding models to see which works best for your data.
Consider fine-tuning your LLM for even better performance.
We have a webinar and article on fine-tuning that can help:
📽️ Create and Fine Tune Your Own Multimodal Model
💻 How to Train and Fine Tune a Multimodal Language Model [+ Use Cases]
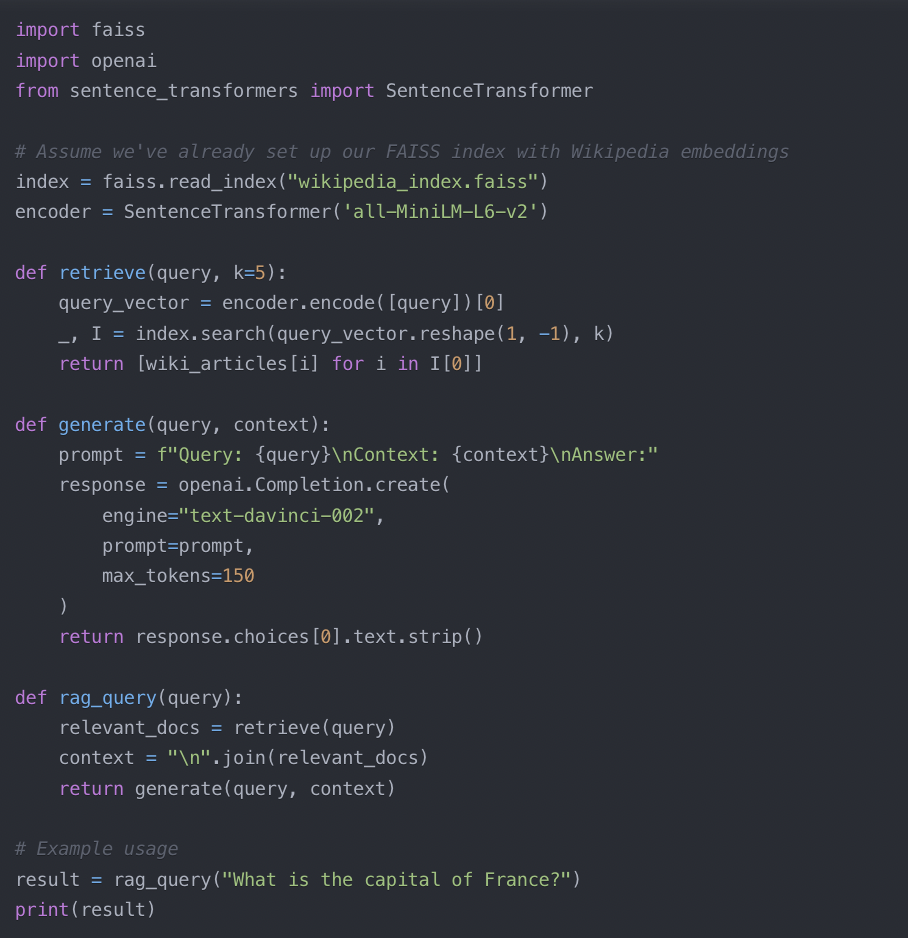
Putting It All Together: An Example with Wikipedia
To see how this works in practice, let’s walk through an example using Wikipedia data for our knowledge base and the OpenAI API for our LLM.
Prepare the Knowledge Base: Start your knowledge bases by downloading a Wikipedia dump and preprocessing the articles. Remove irrelevant sections (like footnotes or metadata) and split longer articles into smaller, more manageable chunks.
Generate Embeddings: Use a model like Sentence-BERT for all-MiniLM-L6-v2 to create embeddings for each article and store these embeddings in a FAISS index.
Implement the Retriever: Set up a retrieval function that uses FAISS to find the most relevant Wikipedia articles for a given query, leveraging approximate nearest neighbor search for speed.
Integrate with the LLM: Use the OpenAI API to generate responses based on the input query and retrieved articles, ensuring that the input is formatted for optimal comprehension by the LLM.
Here’s a basic Python implementation to give you an idea of what this might look like:
Turning It Up a Notch: 3 Ways to Improve RAG LLM Performance
That’s all well and good, but how can we make your Retrieval Augmented Generation LLM more accurate, relevant, and optimized for complex real-world tasks?
Let’s start by using chunk size optimization, re-ranking techniques, and query transformations.
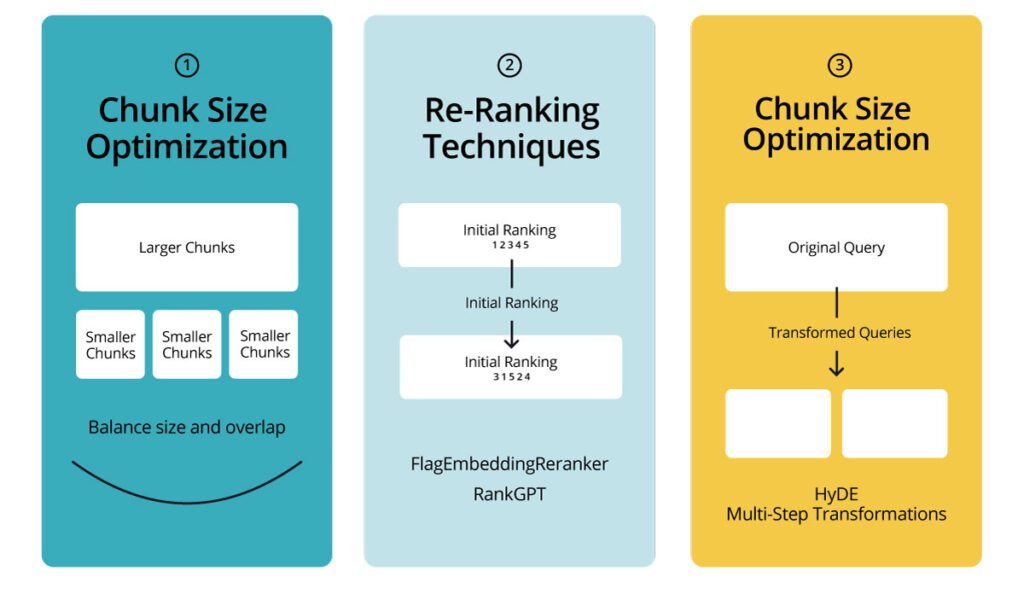
1. Chunk Size Optimization and Customization
Chunk size optimization involves adjusting the size of text segments in your knowledge base to improve context handling and retrieval accuracy.
The ideal chunk size depends on your dataset and use case. For technical documentation, larger chunks might capture complete concepts better, while shorter chunks could suit datasets of brief articles.
Consider balancing chunk size with overlap (the text shared between adjacent chunks). Some overlap maintains context continuity, but too much leads to redundancy.
You can evaluate effectiveness using metrics like retrieval accuracy, response relevance, and processing speed. For example, 256 tokens might work well for general text, while 512 tokens could be better for specialized content.
2. Re-Ranking Techniques
Re-ranking enhances the relevance of retrieved chunks before they’re passed to the LLM. Two notable techniques are FlagEmbeddingReranker and RankGPT.
FlagEmbeddingReranker uses a separate embedding model to re-score initially retrieved chunks based on query similarity.
RankGPT leverages large language models to understand complex query intentions and provide context, potentially leading to more nuanced rankings.
In a legal document retrieval system, re-ranking might help prioritize the most relevant case law or statutes for a given query, even if they weren’t the top results in the initial retrieval.
3. Optimizing RAG with Query Transformations
Query transformation techniques can enhance retrieval outcomes by modifying or expanding the original query.
One way is by using Hypothetical Document Embeddings (HyDE). It involves using the LLM to generate a hypothetical perfect answer to the query, and then using this for retrieval instead of the original query.
There are also multi-step transformations. Those involve breaking down complex queries into simpler sub-queries or expanding vague queries with additional context.
For example, “Compare the economic policies of the US and China” could be broken down into sub-queries about specific aspects of economic policy for each country.
Advanced Techniques for Creating Production-Ready RAG Systems
As you move from experimentation to production, your RAG system needs to be robust, efficient, and scalable.
Let’s explore three advanced techniques that can help you create a production-ready RAG system: hybrid routing, adaptive RAG, and scalability considerations.
Hybrid Routing
Hybrid routing combines multiple routing strategies to optimize performance across different types of queries. Because of this, it can handle diverse information needs more effectively.
For example, you might implement a system that uses keyword-based routing for straightforward queries and semantic routing for more complex ones. Here’s what that might look like:

The result is a more versatile and efficient RAG system that can adapt to different query types.
To level up here, use your LLM to help determine whether a query is simple!
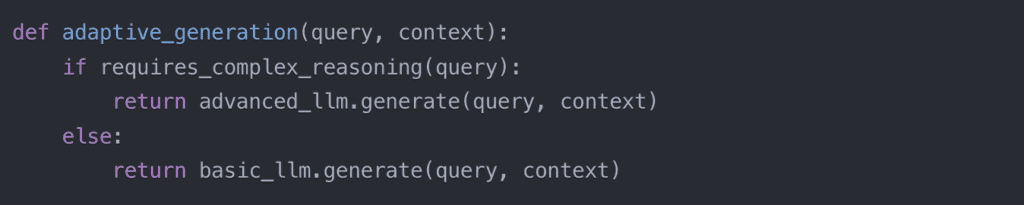
Adaptive RAG
Adaptive RAG takes flexibility a step further by dynamically adjusting its behavior based on various factors such as query complexity, other user input and feedback, or system load. This technique enhances the system’s responsiveness and efficiency.
One way to implement adaptive RAG is by adjusting the number of retrieved documents based on the query’s complexity:

Considering Scalability
Need to increase use of external resources or system capabilities?
Here are key strategies to ensure your system remains performant and reliable at scale:
- Distributed Retrieval: Implement a distributed index across multiple servers to handle large-scale retrieval operations efficiently.
- Caching: Implement a multi-level caching system to store frequently accessed documents and query results, reducing latency and database load.
- Load Balancing: Use load balancers to distribute incoming requests across multiple instances of your RAG system, ensuring even resource utilization and high availability.
- Asynchronous Processing: Implement asynchronous processing for time-consuming tasks to improve system responsiveness.
- Monitoring and Auto-scaling: Implement comprehensive monitoring and auto-scaling capabilities to automatically adjust resources based on demand.
Practical Applications and Use Cases
At HatchWorks AI we believe that in a world where everyone can access generative AI, your data is your biggest differentiator.
So keeping that in mind, what does RAG actually look like when applied to real world use-cases?
Here are three examples of industry use cases.
Healthcare:
RAG can improve clinical decision-making by providing up-to-date information on medical research, patient data, and treatment protocols. Built ground-up with a security and regularity mindset, this can help patients and healthcare workers get more out of their data.
For example, a RAG system can now retrieve information from the latest studies on a rare disease and combine them with patient records to assist doctors in making informed decisions.
Benefits: Enhanced diagnostic accuracy, personalized treatment recommendations, and reduced time in information retrieval.
👉 Explore more: Harnessing RAG in Healthcare: Use-Cases, Impact, & Solutions
Finance:
In finance, RAG can be used to provide real-time insights into market trends, risk analysis, and regulatory compliance. By retrieving the most recent financial news, reports, and data, RAG helps analysts make more informed investment decisions.
Benefits: Improved decision-making, up-to-date market analysis, and faster access to financial insights and processes.
Just look at Morgan Stanley who has adopted a RAG based solution and used it to address questions related to markets, recommendations, and internal processes.
Their financial advisors can now ask this AI assistant questions rather than interrupting another team member’s work to get the information or spending time researching for themselves.

👉 Explore more: RAG in Financial Services: Use-Cases, Impact, & Solutions
E-commerce:
E-commerce platforms can use RAG to enhance product recommendations, customer service, and inventory management.
For example, a RAG system can retrieve data on customer preferences, previous purchases, and product reviews to generate more personalized recommendations.
Benefits: Increased customer satisfaction, higher conversion rates, and better inventory forecasting.
Take our very own client Cox2M who utilized our RAG Accelerator so their customers could get real-time insights about their fleets. That information keeps their customers happy and retained.
Here it is at a glance:

Challenge: Cox2M aimed to create a Generative AI trip analysis assistant for their Kayo fleet management customers, providing real-time, accurate natural language responses about complex fleet data.
Solution: HatchWorks AI developed the Kayo AI Assistant by implementing our RAG Accelerator enabling customers to get real time insights about their fleet through natural language.
Results: The scalable, cost-effective system was delivered on time, enabling easy implementation and scaling across cloud platforms, enhancing fleet management.
Challenges of Using RAG with an LLM (And How to Overcome Them)
Like all AI systems, RAG too has its hiccups. We often see noisy data, ineffective retrieval, and hallucinations as the biggest problems users face. Here’s what those are and simple strategies you can use to overcome them.
Noisy Data
Imagine you’re on a game show where you have to answer questions correctly. Now imagine the audience is allowed to shout out at you what they think the answer is. You could have 50 people all yelling different answers. How easy would it be to hear the right one?
That’s essentially what noisy data is. It clutters up your knowledge base with irrelevant or incorrect information, making retrieval a nightmare.
To combat this, start with aggressive data cleaning. Use tools like regular expressions to filter out formatting issues, and consider implementing a quality scoring system for your documents.
Machine learning models can help identify and flag potential noise, but don’t neglect the power of good old-fashioned human review for your most critical data.
Ineffective Retrieval
If your retrieval system is coming up short, it’s time to sharpen its algorithms. Consider implementing dense retrieval methods that go beyond simple keyword matching.
Techniques like semantic search can help your system understand the context and intent behind queries, not just the words themselves.
Also, don’t underestimate query expansion. Sometimes, the user’s query might not perfectly match the language in your knowledge base. Expanding queries with synonyms or related terms can bridge that gap and improve search results retrieval accuracy.
Hallucinations in Generation
Hallucinations are the AI equivalent of your friend who always embellishes their stories. While creativity is great, we need our RAG systems to stick to the facts.
To keep your RAG AI grounded in facts only, implement fact-checking mechanisms. This could involve cross-referencing generated content with your knowledge base or using a separate model to verify key claims.
You can also experiment with different prompting techniques, like asking the model to cite its sources or to express uncertainty when it’s not confident.
But generally, RAG helps to reduce hallucinations in AI because it supplies such precise data for your system to pull from. So we wouldn’t worry too much about this unless you see it becoming an issue.
RAG Accelerator: Leverage RAG AI without Lifting a Finger
Want to implement RAG into your business but don’t have the time, expertise, or people to make it a reality?
We can do it for you. At HatchWorks AI we’ve built an entire service around RAG so that you can make your data your biggest differentiator.
Our RAG Accelerator dynamically retrieves information using LLMs, ensuring responses are relevant and real-time without the need for extensive training on company data.
The solution can be hosted in your private cloud or on-premise, offering flexibility and security.
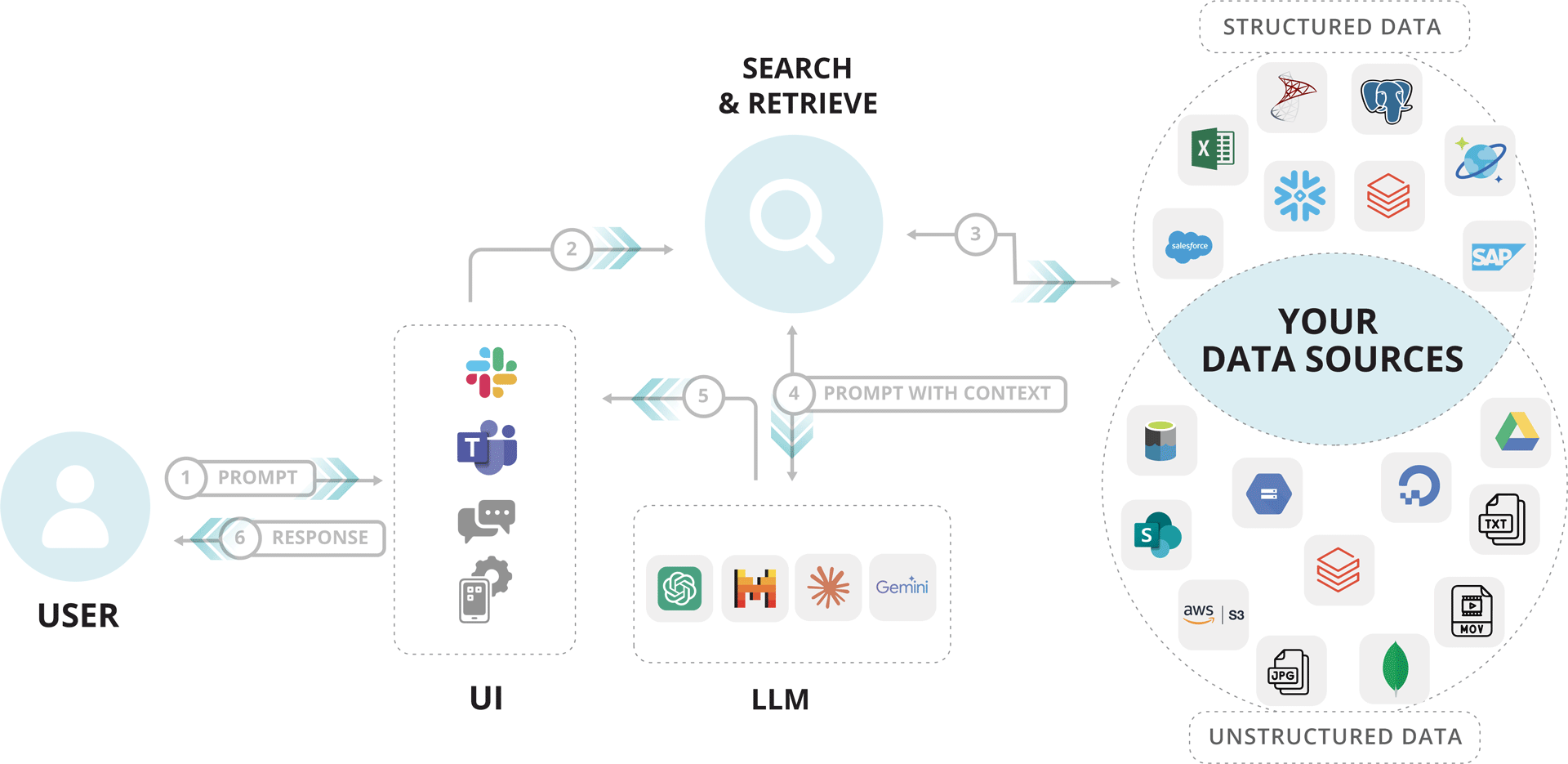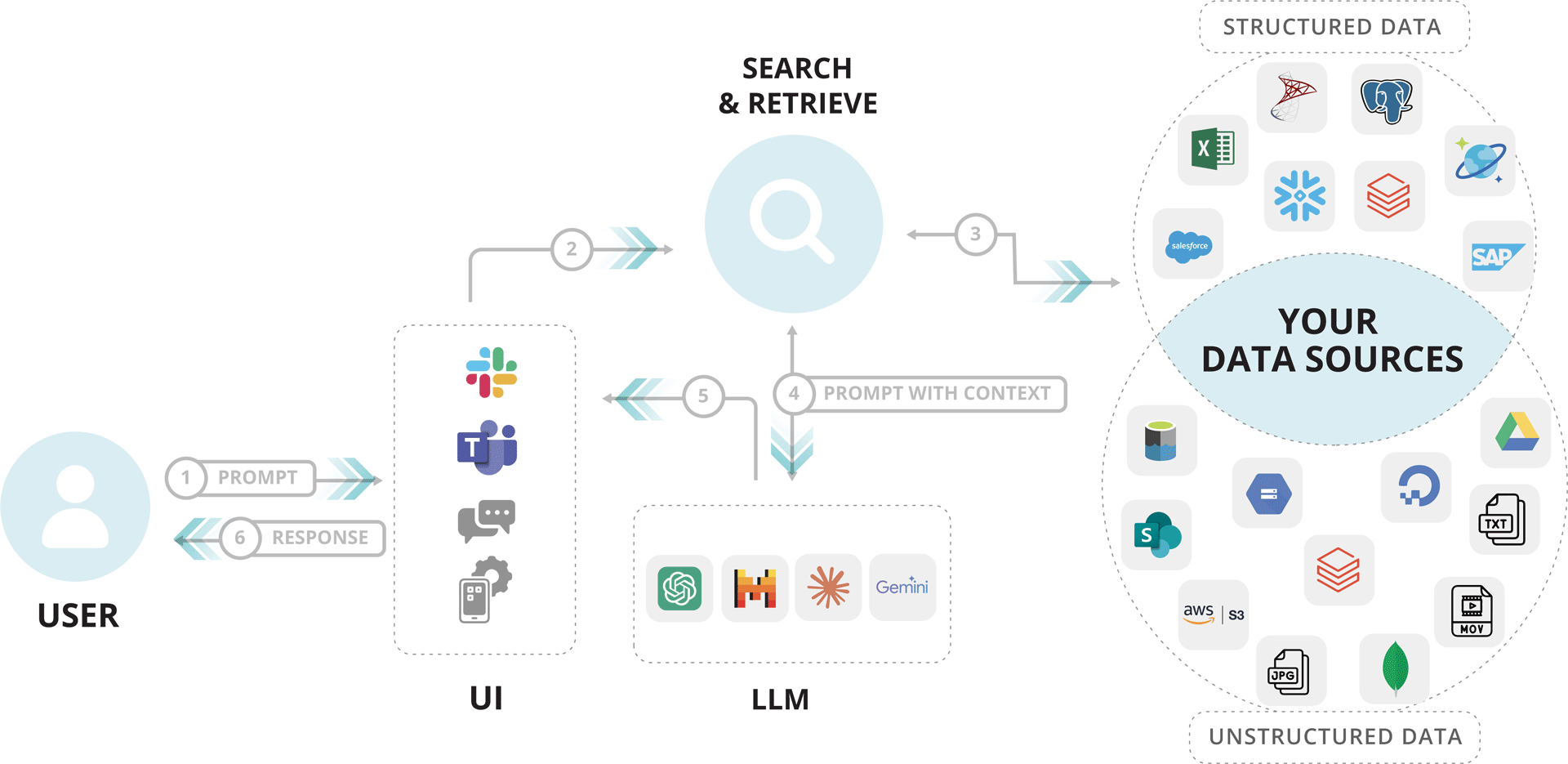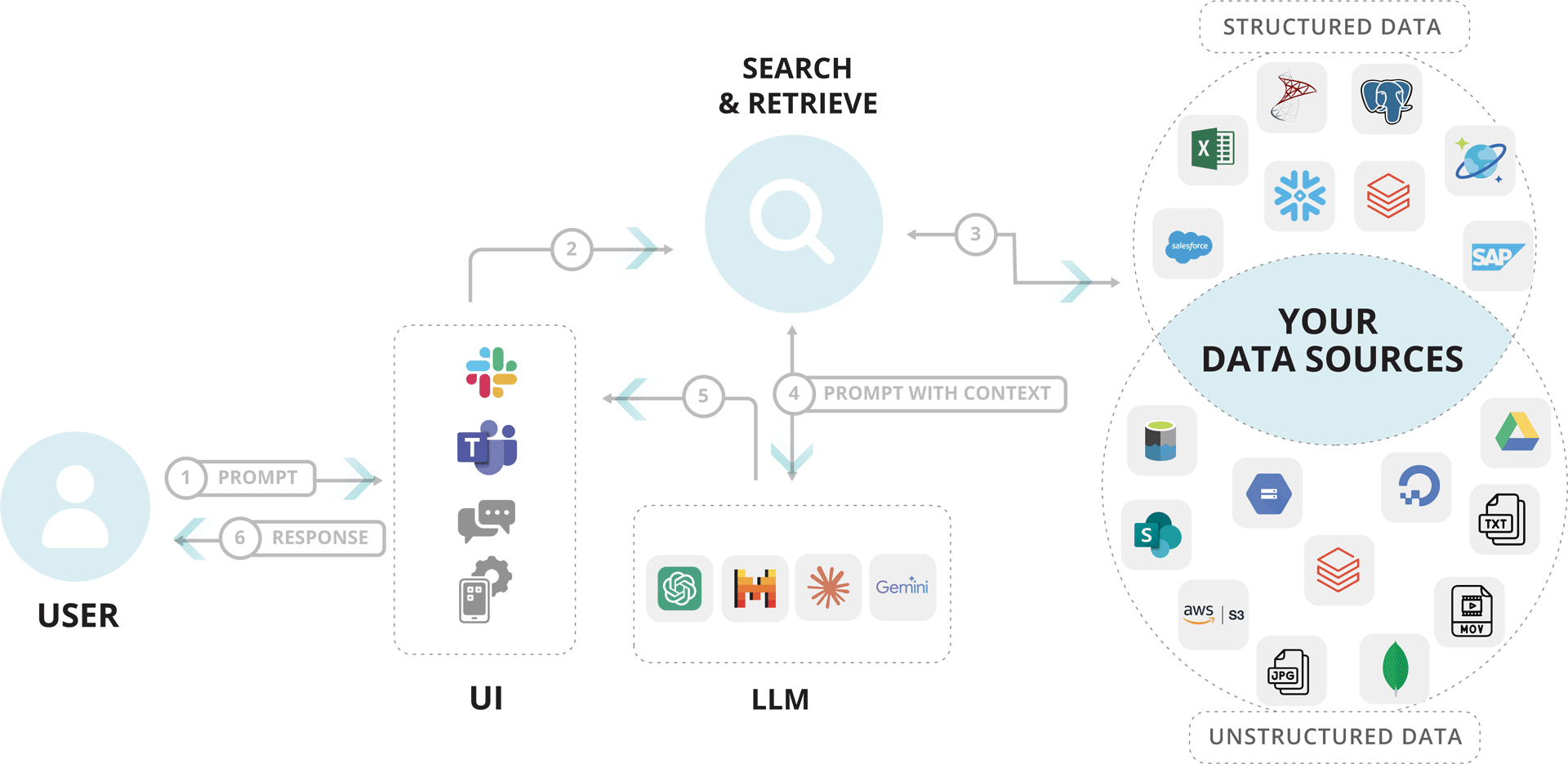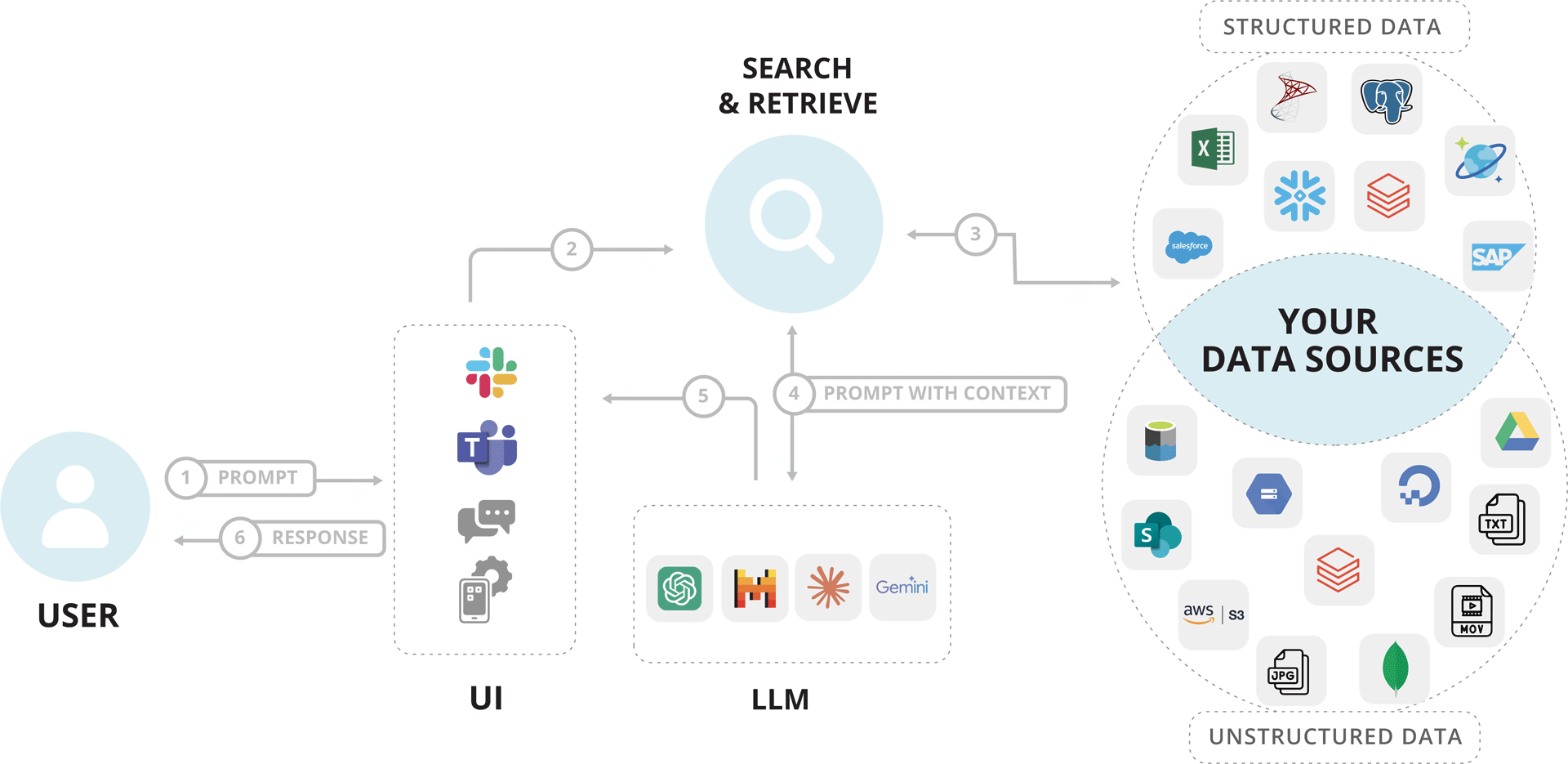
What’s in it for you? You’ll get to:
- access accurate, real-time information through simple, natural language queries
- reduce AI expenses associated with training and fine-tuning
- maintain full control over your proprietary data, ensuring privacy and security
- convert unstructured data like PDFs and images into interactive, insight-driven experiences
- minimize AI hallucinations by leveraging the most relevant and up-to-date information from your data
Head to our service page to learn more about how we can help you or get in touch with us here to set up a call.
Turn Your Data Into a Differentiator
Access the power of AI in your enterprise with our RAG Accelerator.



