
Is your organization’s data scattered across dozens of disparate systems? Does your analytics team spend more time cleaning data than generating insights—ultimately impacting business processes and business outcomes?
It’s a reality for many businesses who don’t have robust data governance and Master Data Management (MDM) strategy in place. But traditional master data approaches are often time-consuming to create. Which is why we recommend combining MDM tools with Gen AI capabilities to achieve effective data management and operational efficiency.

This article breaks down the process I follow to transform scattered, inconsistent enterprise data into high quality master data that’s AI-ready. We’ll use Gen AI-powered master data governance techniques to improve data quality, reduce poor data quality, and unify data domains.
I’ll show you how to:
- Clean and consolidate data across different systems
- Create “golden records” for a unified view of your data assets
- Use Gen AI to automate complex data matching and enrichment
- Enable natural language querying of your transactional data for faster decision making
I’ll demonstrate these concepts using a real-world example from Baird & Warner, Illinois’ largest independent real estate brokerage, where we tackled bad data and data silos across their residential sales, mortgage financing, and title services divisions.
I’ll also cover the basics of data management, including what master data entities are, why data governance matters for data protection, and key challenges in building a data governance framework without losing momentum on your digital transformation.

📽️Go Deeper with Our Webinar
Want to see this process in action?
Watch our full one-hour webinar in which we walk through each step in detail.
What is Master Data Management (MDM)?
Master Data Management (MDM) is the process of organizing and maintaining key reference data—like customer data, product, or employee information—in a single, consistent, and accurate system.
It ensures everyone in the organization works with the same trusted data, improving decision-making, operations, and customer experiences.
Let’s bring it to life a little. Imagine your company as a bustling city, with departments as individual neighborhoods. Now, think of Master Data Management (MDM) as the city’s central command center that keeps everything running smoothly.
In this city, vital information about customers, products, suppliers, and employees flows like traffic through different streets (your various systems). But without proper management, this information can get tangled, duplicated, or lost.
That’s where MDM steps in. It’s like having a brilliant traffic control system that:
- Guides all information to a central hub
- Cleans up the messy parts
- Makes sure everyone is speaking the same language
Let’s say Sarah Johnson is a customer who appears in your systems as:
- “S. Johnson” in your CRM
- “Sarah J.” in billing
- “Sarah Johnson-Smith” in customer support
MDM is able to recognize these are all the same person and create one clear, accurate profile. This way, when any department needs to know about Sarah, they’re all working with the same, up-to-date information.
MDM’s Key Processes—What It Needs to Really Work
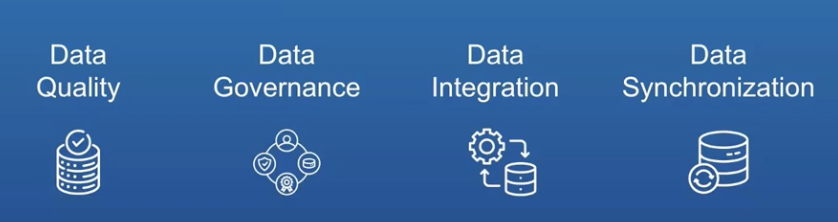
Successful master data management rests on four pillars: high-quality source data, seamless system integration, real-time synchronization across platforms, and robust governance policies that maintain data integrity.
Let me break down these four foundational pillars of MDM:
Data Quality
Raw data must meet baseline standards before entering the MDM system. This means accurate, complete, and properly formatted information from every source system, whether it’s customer records from your CRM or inventory data from your warehouse system.
Data Integration
All your business systems—from ERP to CRM to legacy databases—must be connected to your MDM platform through reliable data pipelines. This ensures that data flows smoothly between systems without manual intervention, preventing information silos and redundant data entry.
Data Synchronization
Changes in one system must automatically reflect across all connected platforms. When a customer updates their address in your support portal, that change should cascade through your billing, shipping, and marketing systems instantly, maintaining consistency across your entire data ecosystem.
Data Governance
This is your rulebook for data management—clear policies and procedures that define:
- Who can create, modify, or delete master data
- How data quality and data protection are measured and maintained
- When and how data should be updated
- Which standards must be followed for data entry
- How compliance is monitored and enforced by data stewardship
If one pillar falls, the MDM is compromised. But why does that matter at all?
Why Bother with MDM? Core Benefits and Who it Helps
Master data management creates a unified, accurate “single source of truth” for critical data. That then drives better decisions, operational efficiency, and AI/ML readiness—everything a modern business needs to thrive in their industry without bleeding cash and wasting time.
In the picture below, you can see four key personas with the data problems they face in their roles.

Question is, how does master data management solve those problems?
For Teresa the Tech Exec:
Master data management provides Teresa with trustworthy data pipelines, enabling predictive analytics, AI initiatives, and smarter automation strategies.
For Santiago the Data Steward:
With master data management, Santiago gets automated data cleansing, deduplication, and data governance. This reduces manual intervention, improves SLA compliance, and minimizes errors caused by legacy systems.
For Deborah the Data Analyst:
Master data management’s centralized “golden records” give Deborah full context for data. With consistent definitions and lineage tracking, she spends less time untangling data messes and more time on analysis.
For Bob the Business Leader:
MDM turns disjointed data into accessible, real-time insights. Bob can finally act on accurate, cross-departmental data, leading to better forecasting and faster revenue wins.
Challenges of MDM: Common Roadblocks to Data Excellence
While MDM promises a single source of truth, organizations often face significant hurdles in implementation and maintenance.
Let’s explore the challenges that can derail even well-planned MDM initiatives:
Data Silos: The Walls Between Systems
Department-specific applications, legacy systems, and disconnected databases create isolated pockets of information. These silos not only duplicate data but often contain conflicting versions of the same information. When Marketing’s customer data doesn’t match Sales’ records, who has the right version?
Data Quality: Garbage In, Garbage Out
Poor data quality is like a virus that spreads through systems. Incorrect entries, outdated information, and inconsistent formats create a ripple effect of problems. When customer addresses are entered in multiple formats or product codes don’t match across systems, the resulting chaos affects everything from shipping to analytics.
Governance Gaps
Without clear and effective data governance, MDM becomes a free-for-all. Questions arise like:
- Who can create new master data records?
- What standards should be followed?
- How are changes tracked and approved?
- Who resolves data conflicts?
Domain Overlap Confusion
When business and data domains intersect, complexity multiplies. A customer might also be a supplier, or a product might exist in multiple categories. These overlapping domains create confusion about which system owns what data and how relationships should be managed.
Change Management Resistance
Implementing MDM often requires changing how people work. Employees comfortable with their own spreadsheets and processes may resist new systems and standards. Training needs, process changes, and cultural shifts can slow or derail MDM initiatives.
Integration Complexity
Connecting diverse systems isn’t just a technical challenge—it’s a business puzzle. Each integration must consider:
- Different data models and formats
- Legacy system limitations
- Real-time vs. batch updates
- Security requirements
- Performance impacts
Multiple Definitions: The Language Barrier
What seems simple—like defining a “customer” or “active account”—can spark heated debates. When different departments have their own definitions for basic concepts, creating standardized master data becomes a significant challenge.
The Role of Generative AI in MDM
Traditional MDM is the backbone of data management, but Generative AI is making it faster and easier to execute.
Let’s examine how GenAI transforms key MDM activities:
Data Quality & Enrichment
| Without Gen AI: | With Gen AI: |
|---|---|
|
Manual rules for data validation
|
Intelligent anomaly detection that learns from patterns
|
|
Time-consuming creation of data standards
|
Automated generation of data quality management rules
|
|
Basic pattern matching for inconsistencies
|
Rich content generation for incomplete records
|
|
Heavy reliance on human review for complex cases
|
Self-improving validation that adapts to new data patterns
|
Data Matching & Deduplication
| Without Gen AI: | With Gen AI: |
|---|---|
|
Rigid matching rules based on exact criteria
|
Context-aware matching that understands variations
|
|
Limited ability to handle variations in text
|
Smart entity resolution across languages and formats
|
|
Manual review needed for uncertain matches
|
Confidence scoring for potential matches
|
|
Static matching algorithms
|
Adaptive matching that improves over time
|
Data Governance
| Without Gen AI: | With Gen AI: |
|---|---|
|
Manual policy creation and enforcement
|
Automated policy suggestions based on data patterns
|
|
Reactive issue detection
|
Proactive issue prevention
|
|
Fixed business rules
|
Dynamic rule generation and adaptation
|
|
Limited scalability of governance processes
|
AI-powered compliance monitoring
|
Now let’s look at what all that means for Teresa, Deborah, Santiago, and Bob.

How to Use Gen AI for MDM
In the webinar, we looked at a real problem for a very real company: Baird & Warner, Illinois’ largest independent real estate brokerage. They have services for residential sales, mortgage financing, and title services.
Their problem: With so many services, data is prone to silos, duplications, inconsistencies, and incomplete records. This limits their ability to maintain a “single source of truth” across systems.
Our goal: Use generative AI to break down these data silos, improve data accuracy, and streamline master data management (MDM) processes.
But let’s get more specific about our desired outcomes. We want to:
- Use generative AI to automate the identification and merging of duplicate records across disparate data sources. Given that 50-80% of a data manager’s time is typically spent on these tasks, automation will free up data managers to focus on higher-value work.
- Build a unified concept of a “household” by consolidating client data from three enterprise resource planning (ERP) systems:
- Baird & Warner’s ERP (property sales data)
- Key Mortgage’s ERP (mortgage data)
- B&W Title’s ERP (title services data)
- Use Retrieval Augmented Generation (RAG) to enable natural language queries of the data. This allows users to have conversations with the data, making it easier to get useful insights.
⏸️While we’re exploring this use-case, keep in mind using Gen AI for MDM is applicable across industries, from financial services to healthcare.
Now, let’s look at the process step-by-step.
Step 1: Consolidate and Upload Data
We’re pulling data from the three key ERPs:
- Property Sales Data (from Baird & Warner’s ERP)
- Client Data (from Key Mortgage’s ERP)
- Mortgage & Title Data (from B&W Title’s ERP)
We need to upload these datasets into a shared environment where generative AI tools can access and analyze them collectively. This will show us who across sources fits within a single household.
Step 2: Transform Data Into Numerical Values
We can’t leave the data in its current form. If we did, we wouldn’t be able to analyze it using machine analysis. To convert the data and read it, we need to use an embedding model.
Here’s how it works:
- Each data entry (like a name, address, or phone number) is represented as a point in a vector space.
- Embeddings allow for mathematical operations, like calculating the “distance” between two points.
- This process transforms abstract text data into measurable, analyzable points, enabling easier similarity detection and classification.
Why this matters: It’s hard for raw text to be compared directly, but vectorized data points allow AI to measure how “close” two records are, even if names, addresses, or other data are misspelled or formatted differently.
What you get is something that looks like this:
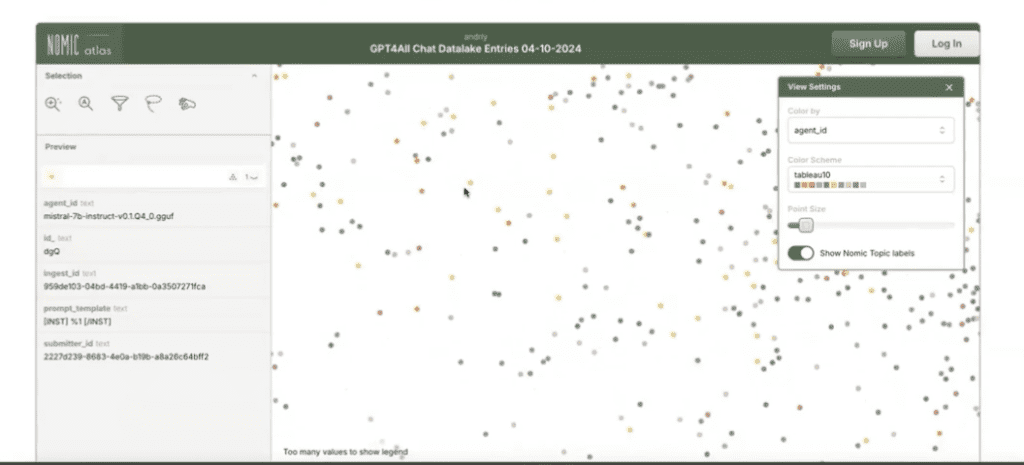
To replicate this step, you will need to access a tool like: OpenAI Embeddings API, Hugging Face Transformers, or custom-trained vector embedding models.
Step 3: Similarity Search for Record Matching
We need to calculate the distance between points to find out which ones are close. The closer the dots, the closer the data is in similarity. And if the data is similar, then there is likely overlapping information that can be consolidated for cleaner, easier to read records.
Remember, we want to identify which records are similar enough to potentially belong to the same household or client.
Here’s what will happen at this stage:
- The system identifies points that fall under a specific similarity threshold.
- Records that are “close” to each other (below a certain threshold) are flagged as potential duplicates or household matches.
- The flagged records are sent to a large language model (LLM) (like ChatGPT) to verify their relationship. The LLM is prompted with the following query:
Prompt: “Are these two entries the same person or the same household? Respond with ‘Same person’, ‘Same household’, or ‘No’.”
This LLM-driven verification step ensures that only legitimate matches are processed further.
The tools you’ll need to complete this step include: OpenAI’s ChatGPT, Anthropic’s Claude, or other LLMs with API access.
Step 4: Assign Household IDs to Relevant Data
Once the system verifies that certain records belong to the same household, the following steps occur:
- Each “household” is assigned a unique Household ID.
- All associated entries from the Property, Mortgage, and Title systems are linked under this Household ID.
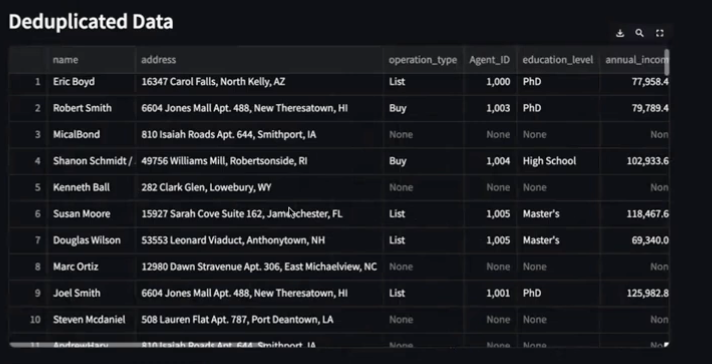
Why this matters:
This “household view” enables Baird & Warner to have a single, unified understanding of each client’s relationship across sales, mortgage, and title services. It allows for better customer experiences and streamlined service delivery.
It also eliminates duplicate data from the system for an overall cleaner data source.
Step 5: Use RAG to Explore the Data
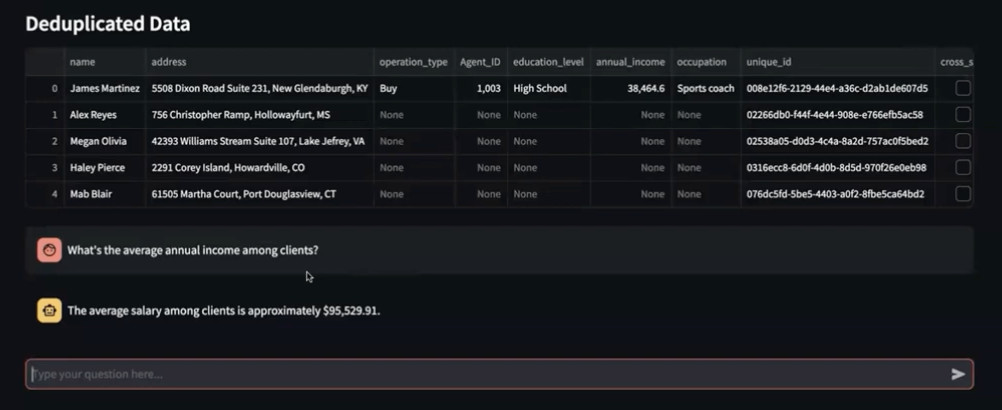
It’s all well and good to clean up and consolidate your data but the real value is in accessing it. RAG, or retrieval augmented generation, lets you access your up-to-date proprietary data through a chatbot interface.
All you need to do is plug in questions to the chatbot and get information back that you can use to take action in your business. For example, we asked our RAG chatbot:
- What’s the average annual income among clients?
- What is the minimum salary among clients with multiple services?
- What is the ID of the agent that was able to do more cross sales?
The chatbot uses the data to provide answers in seconds.
Not sure where to start when it comes to using retrieval augmented generation? Check out our RAG resources:
- The CTO’s Blueprint to Retrieval Augmented Generation (RAG)
- RAG: What YOU Need to Know to Apply AI at Work
- RAG for Technology: Use-Cases, Impact, & Solutions
- RAG for Communications: Use-Cases, Impact, & Solutions
- Harnessing RAG in Healthcare: Use-Cases, Impact, & Solutions
- RAG in Financial Services: Use-Cases, Impact, & Solutions
- RAG for Retail: Use-Cases, Impact, & Solutions
Let’s Get Your Data AI-Ready
Struggling with poor data quality, siloed data, or a fragmented data governance team? HatchWorks AI can help you modernize your data governance program and orchestrate master data management solutions. By treating your data as a strategic asset and aligning it under a cohesive data governance framework, you’ll unlock new value—fast.
From unifying customer data to establishing a robust data governance initiative, our experts guide you through the data lifecycle, ensuring that data governance establishes policies for data protection and that you never lose track of your data model. Whether you’re just starting out or have a mature governance program, we’ll tailor the right approach to your business stakeholders and use cases.
Let’s Build Your AI Strategy
Meet with our AI experts to explore your goals and challenges.
We’ll work with you to create a tailored AI Strategy and Roadmap that turns AI into ROI.



