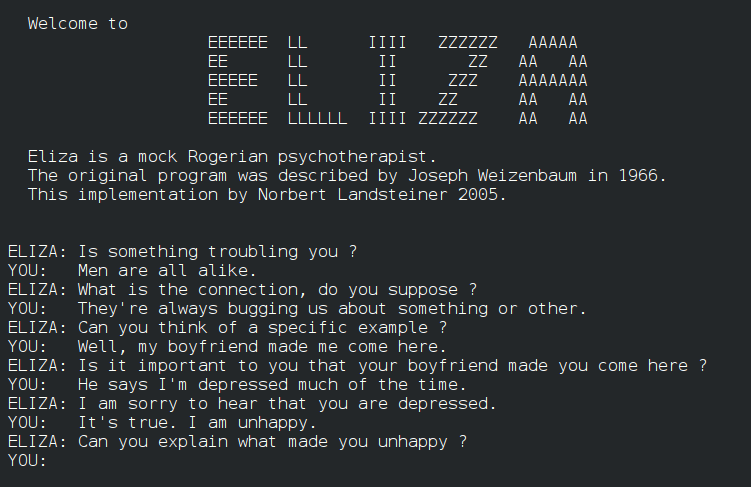
The first chatbot created by Joseph Weizenbaum, simulating a psychotherapist in conversation.
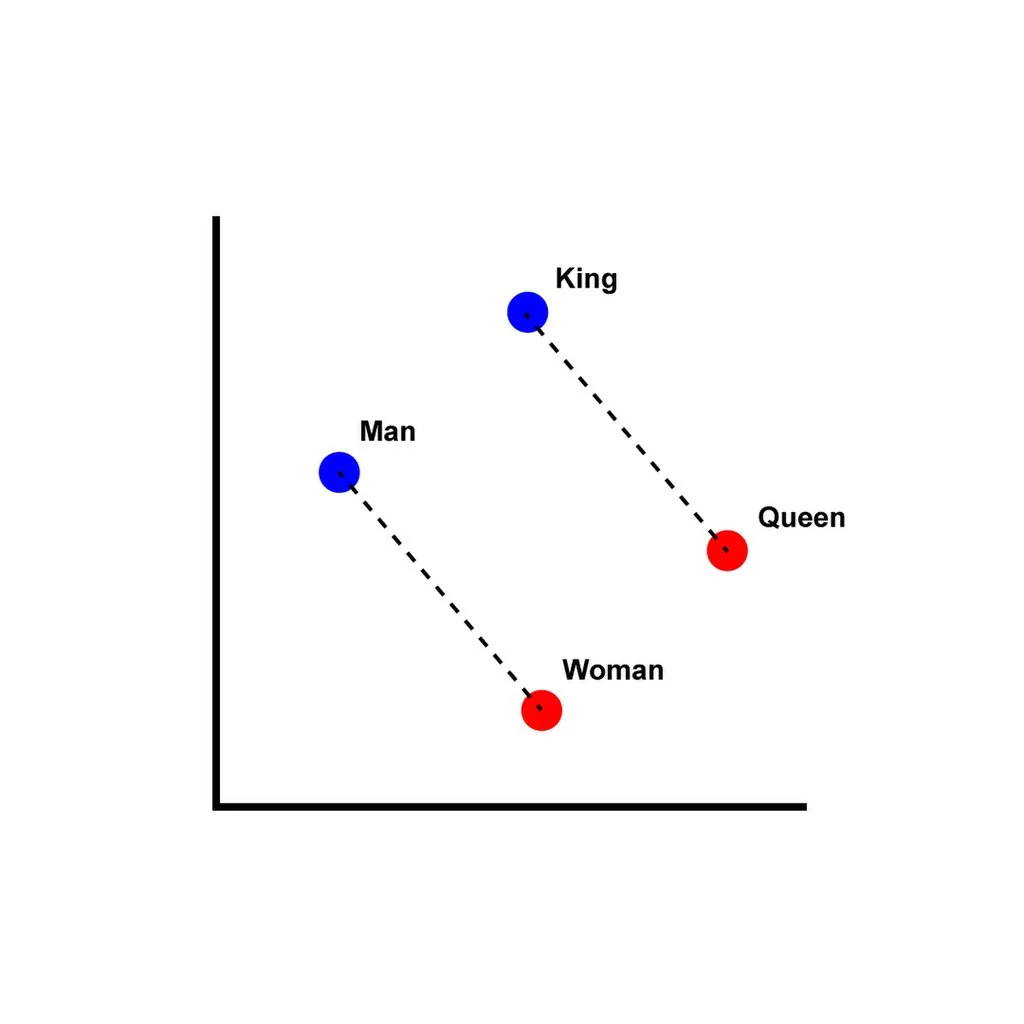
A groundbreaking tool developed by a team led by Tomas Mikolov at Google, introducing efficient methods for learning word embeddings from raw text.
OpenAI released GPT-3, a model with 175 billion parameters, achieving unprecedented levels of language understanding and generation capabilities.
OpenAI introduced ChatGPT, a conversational agent based on the GPT-3.5 model, designed to provide more engaging and natural dialogue experiences. ChatGPT showcased the potential of GPT models in interactive applications.

The launch of Midjourney, along with other models and platforms, reflected the growing diversity and application of AI in creative processes, design, and beyond, indicating a broader trend towards multimodal and specialized AI systems.
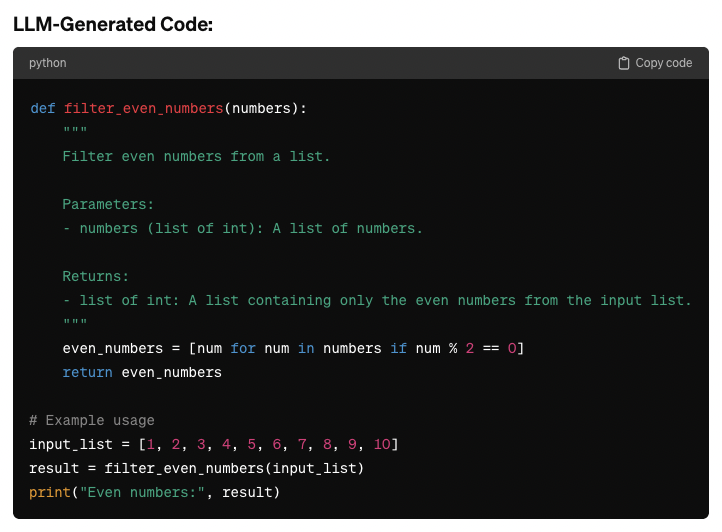
Here’s an example to illustrate how LLMs can be used for automated code generation:
Prompt:
“Write a Python function that takes a list of numbers as input and returns a list containing only the even numbers.”
Here’s an example to illustrate how LLMs can be used for text generation:
Prompt:
“Generate a product description for a cutting-edge smartwatch designed for fitness enthusiasts. The description should highlight its advanced health and fitness tracking, personalized coaching, long battery life, durability, connectivity features, and customizable design. Target the description to appeal to both seasoned athletes and beginners interested in tracking their fitness progress.”

Here’s an example to illustrate how LLMs can be used for language translation:
Prompt:
“Translate the following English text into Spanish: ‘The quick brown fox jumps over the lazy dog.'”

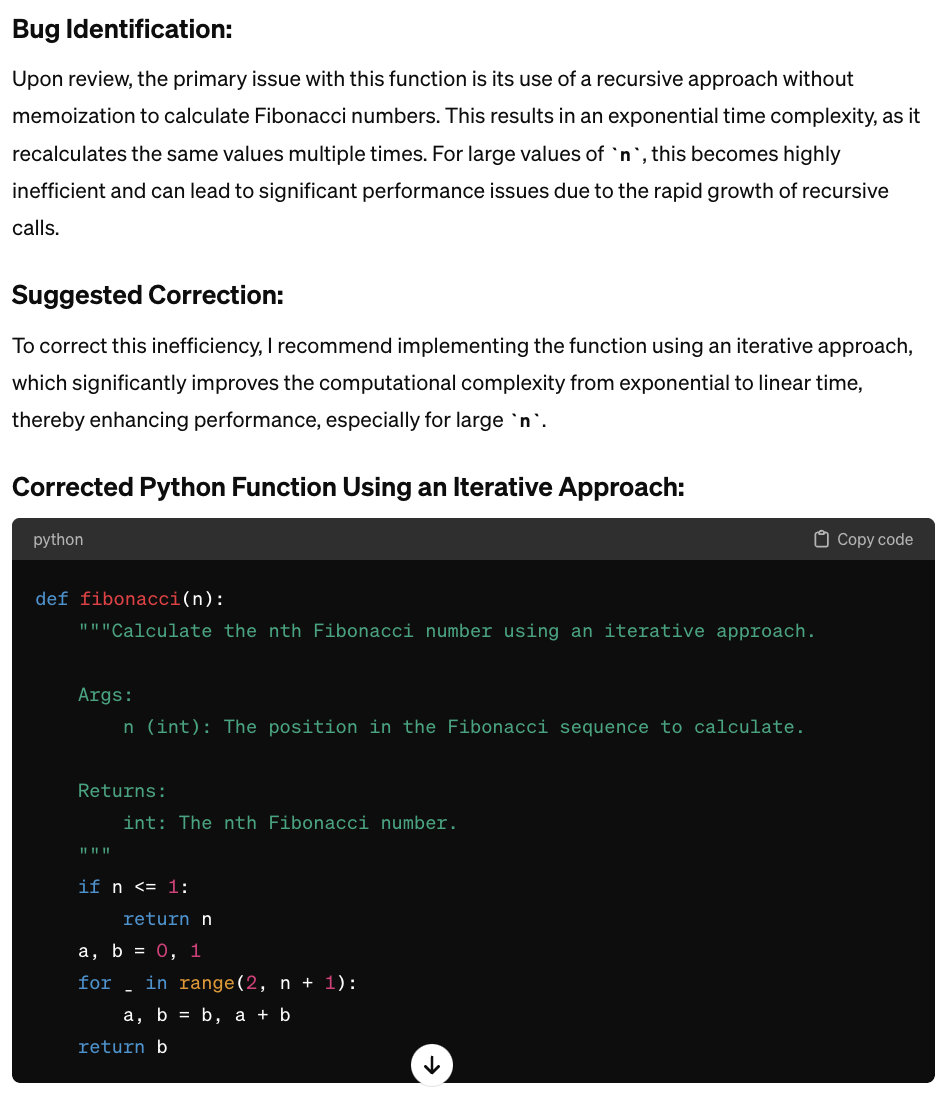
Here’s an example to illustrate how LLMs can be used for bug detection:
Prompt:
“The Python function below intends to return the nth Fibonacci number. Please identify and correct any bugs in the function.
Python Function:
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n – 1) + fibonacci(n – 2)”
Here’s an example to illustrate how LLMs can be used for paraphrasing:
Prompt:
“Rewrite the following sentence in a simpler and more concise way without losing its original meaning: ‘The comprehensive study on climate change incorporates a wide array of data, including historical weather patterns, satellite imagery, and computer model predictions, to provide a holistic view of the impacts of global warming.'”