
Data teams are under pressure to make the right infrastructure call, but with more tools, more external data sources, and rising AI expectations, the path forward isn’t always clear.
Choose wrong, and you risk slow insights, inefficient data processing, siloed systems, or data that’s unusable when it matters most.

This guide breaks down the real differences between data lakes, warehouses, and marts so you can build a data storage foundation that’s ready for what’s next.
Data Lakes, Data Warehouses, and Data Marts: At a Glance
Before diving too deep into their strategic roles, let’s define each concept in simple, practical terms.
The Data Lake: a centralized repository designed to store massive volumes of data in its raw form.
That includes structured data (like tables), semi-structured data (like JSON), and unstructured data (like video, audio, and logs). There’s no upfront schema, just flexible, scalable storage ready for data science, machine learning, or any future use case you haven’t thought of yet.
The Data Warehouse: stores structured, processed data optimized for fast, repeatable querying.
It follows a schema-on-write model, meaning data is cleaned and organized before it’s stored. This makes it ideal for business intelligence, reporting, and scenarios where accuracy, consistency, and performance matter most.
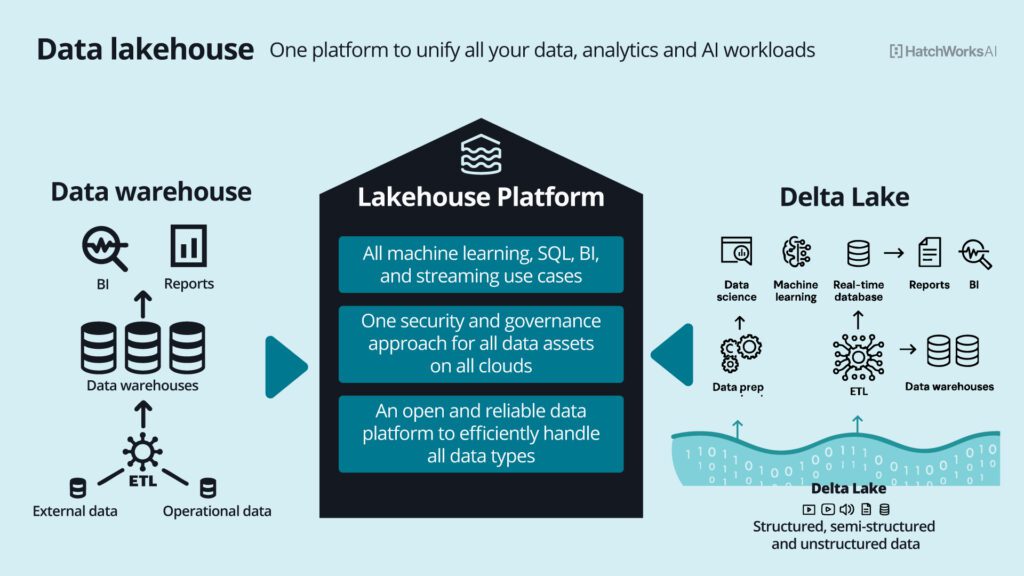
Sometimes, a data lake and a data warehouse can be combined. Databricks unites the two in it’s Lakehouse platform:
The Data Mart: a focused slice of a data warehouse or lake, designed to meet the specific needs of a department or business function.
It contains curated data that’s been filtered and summarized for a defined purpose, like campaign analysis for marketing or revenue tracking for finance.
Think of it as a lightweight, use-case-driven layer that brings relevant insights closer to the people who need them.
The Key Differences between Data Lakes, Data Warehouses, and Data Marts
Now that you know what each one is, here’s how they actually compare across the areas that shape your data strategy.
Storage and Structure
| Type | Description |
|---|---|
|
Data Lakes
|
Store everything in raw form (structured, semi-structured, unstructured). No upfront schema required, highly flexible.
|
|
Data Warehouses
|
Hold structured, cleaned, and transformed data. Structure defined early for consistent analysis.
|
|
Data Marts
|
Contain a focused slice of structured data tailored for specific use cases or teams, typically sourced from lakes or warehouses.
|
Use Cases and Users
| Type | Description |
|---|---|
|
Data Lakes
|
support exploratory analysis, machine learning, and large-scale processing. They’re commonly used by data scientists and engineers who need access to raw or complex data types.
|
|
Data Warehouses
|
built for repeatable reporting, dashboards, and business intelligence. Analysts and BI teams rely on them for structured, fast answers.
|
|
Data Marts
|
deliver targeted insights to specific teams like sales, finance, or marketing. They’re designed to be easy to use, with only the data that matters most to that group.
|
Flexibility and Adaptability
| Type | Description |
|---|---|
|
Data Lakes
|
offer high adaptability. You can store data now and decide how to use it later, making them ideal for evolving needs.
|
|
Data Warehouses
|
trade some flexibility for consistency. Once a schema is set, changes become harder, but analysis is faster.
|
|
Data Marts
|
limited by design. They serve immediate needs but aren’t meant to stretch beyond their defined scope.
|
Performance and Scale
| Type | Description |
|---|---|
|
Data Lakes
|
scale easily for massive datasets but may require additional tools to optimize query performance.
|
|
Data Warehouses
|
optimized for fast, structured queries, though scaling them can increase cost and complexity.
|
|
Data Marts
|
offer fast performance for focused workloads, but aren’t built to handle enterprise-wide data needs.
|
Governance and Complexity
| Type | Description |
|---|---|
|
Data Lakes
|
require strong governance to stay usable. Without proper controls, they can quickly become chaotic and hard to navigate.
|
|
Data Warehouses
|
easier to govern due to their structure, which enforces rules around data quality and access.
|
|
Data Marts
|
simpler to manage on their own, but rely on upstream systems for consistency and compliance.
|
You don’t always need all three, but you might grow into them.
If you’re early in your data strategy, it’s normal to start with just one. Many teams begin with a data warehouse to support data access, data analytics, business intelligence, and dashboards. It’s structured, governed, and familiar.
If you’re exploring machine learning models or building AI products, you’ll need a data lake. Warehouses aren’t built to handle the scale or variety of raw data that AI workflows depend on.
If your departments need fast, scoped access to their own data, independent data marts can give teams like marketing or sales their own self-serve analytics without giving them the keys to the full warehouse.
Most mature organizations use all three. But coordinating those environments takes clear roles and responsibilities. This breakdown on Understanding Data Governance Responsibilities can help define who owns what in a modern data stack.
A few decision cues to guide you:
- Working with raw, unstructured, or streaming data? Start with a data lake. It’s built for flexibility and scale.
- Need fast, reliable reporting on clean, structured data? A warehouse gives you performance and consistency.
- Want to empower a specific team with relevant insights? A data mart gives them just what they need.
But your choice will require a better understanding of each. So let’s spend some time exploring the nitty gritty details of data lakes, data warehouses, and data markets.
A Deep Dive into the Data Lake: Features and Benefits Explained
A data lake is designed to hold everything—raw data, at scale, in its original format. It’s not built for a single function or team. It’s built to be flexible.
Where a data warehouse asks for structure upfront, a data lake simply asks: What do you have?
It stores structured data (like tables), semi-structured data (like JSON or XML), and unstructured data (like images, logs, or audio). That makes it a natural fit for organizations that collect and store data generated in large amounts, such as web server logs and sensor data.
It doesn’t process or transform data on its own. Instead, it acts as a centralized reservoir that other platforms and teams can access. Whether you’re running reports, building models, or storing data for compliance, the lake is where it lives first.
Core Features of Data Lakes
So, what exactly makes a data lake architecture different under the hood? Here are a few defining characteristics that separate it from other platforms.
- Stores raw, unfiltered data in native formats
No need to define a schema at the start. You can shape the data when you’re ready to use it. - Supports multiple data types
Structured rows, semi-structured files, and unstructured content. That’s data stored side by side, without conflict. - Scales effortlessly
Designed to handle petabytes of data without breaking down, especially when paired with cloud-based or MPP infrastructure. - Integrates with modern data platforms
Compatible with tools used for querying, visualization, transformation, and advanced analytics.
Benefits of Using a Data Lake
The biggest benefit of a data lake is flexibility. But that flexibility unlocks a lot more than just raw storage. Here’s what organizations actually gain when they put a data lake at the center of their business data ecosystem:
- Scalable storage without high upfront cost
- “Ingest now, decide later” flexibility
- Centralized access for multiple teams
- Support for unstructured and complex data types
- Real-time insights with the right processing tools
- A foundation for machine learning and GenAI
Because lakes don’t require upfront transformation or modeling, you can store petabytes of raw data without driving up processing costs. It’s a structure that supports scale without overcommitting to structure too soon.
That’s especially useful when the future value of data isn’t fully known. Maybe you’re not building models today, but you want the option tomorrow. With a data lake, you can ingest first and decide later.
It also reduces redundancy. Instead of creating different pipelines or storage systems for every team, everyone can work from the same data. Each group can extract data and shape what they need.
Critically, lakes support the kinds of data that warehouses can’t handle easily. If your business deals in unstructured content, a lake gives you space to store and explore it without compromise.
And while lakes aren’t built for fast querying out of the box, they pair naturally with tools such as Databricks to deliver performance at scale. That’s where you unlock real-time analytics and AI-powered exploration.
Finally, data lakes are what make AI and GenAI possible in practice. They provide the raw inputs that feed into modern use cases like Retrieval-Augmented Generation, prompt evaluation, and feedback loops.
When to Use a Data Lake?
👉 Use a data lake when you’re working with raw, messy, or high-volume data (and you don’t want to limit how it’s used later).
Inside the Data Warehouse: Features and Benefits Explained
While a data lake is designed to store anything, a data warehouse is built to answer something. Mainly, they are used to store historical data that’s already been cleaned, modeled, and organized for data analytics.
They support dashboards, monthly reporting, performance reviews, and regulatory audits.
Unlike lakes, which take in everything, warehouses are selective. Data is transformed before it arrives, so by the time users query it, it’s already standardized and governed. That makes it a trusted source across teams, especially when consistency matters more than flexibility.
Many organizations already have an existing data warehouse in place, especially if they’ve invested in BI tooling or built out reporting infrastructure. The challenge there is how to evolve it. As data needs grow and teams demand more flexibility, the warehouse often becomes part of a broader architecture that includes lakes and marts.
Core Features
A modern data warehouse focuses on structure, speed, and trust. Here’s what defines it:
- Structured data storage optimized for analytics: Data is organized into tables and columns, aligned to specific business logic and reporting needs.
- Supports batch-based data ingestion: Often built around scheduled loads and updates that power recurring reports and dashboards.
- Optimized for OLAP (Online Analytical Processing): Warehouses are designed to quickly and consistently support analytical queries across large, structured datasets.
- Governed and secure by default: With schema enforcement, access controls, and audit trails built in, warehouses are often central to compliance workflows.
Benefits of Using a Data Warehouse
With structure comes reliability. Here’s what your teams gain when your data lives in the right format, in the right place:
- Fast, consistent performance for everyday queries
- A single, trusted source for business data
- Data that’s vetted, governed, and audit-ready
- Accessible tools for analysts and business users alike
- Seamless data integration with your existing warehouse
Because data is cleaned and structured before it ever hits the warehouse, you can trust what comes out. Whether it’s a monthly revenue dashboard or an executive report, users get consistent numbers.
That consistency matters beyond performance. A shared schema gives teams across the business one language to work from. Marketing and finance may look at different slices, but they’re slicing from the same source.
Governance is another built-in strength. Warehouses enforce structure on the way in, so what you report out is already vetted. That’s essential for teams navigating compliance requirements, financial disclosures, or regulatory oversight.
They’re also accessible. With SQL at the core and plug-and-play integrations into BI tools like Tableau, Power BI, and Looker, both technical and non-technical users can explore data confidently.
And if you already have an existing data warehouse, you won’t need to start from scratch. Instead, it can evolve to support a broader ecosystem.
Curious how governance fits into a broader data strategy? We break it down in Data Strategy vs. Data Governance in 2025.
When to Use a Data Warehouse?
👉 Use a data warehouse when the goal is clean, consistent reporting across teams.
Browsing the Data Mart: Features and Benefits Explained
Data marts are ideal for users who want to analyze data for their specific business unit or department. Sales, finance, marketing, and HR can each have their own tailored view of the data, without the overhead of navigating broader systems.
Because data marts filter out everything unrelated to the task at hand, they simplify access and improve speed. Teams don’t have to dig through irrelevant datasets or wait for IT to surface insights. The right data is already there.
Core Features
These focused environments are built for speed, clarity, and control:
- Department-specific scope
Each data mart contains only the data relevant to one team or function. - Streamlined structure for targeted use cases
The schema is simplified, making it easier for business users to run their own queries or generate reports. - Pulled from broader sources
Marts often source their data from a central warehouse or lake, meaning they inherit structure and governance without duplicating effort.
Benefits of Using a Data Mart
When business teams hit walls trying to get the data they need, a data mart clears the path. These are the benefits they unlock when the data is already tailored to their needs.
- Faster performance for department-level queries
- Less strain on your core data warehouse
- Simpler access for business teams
- Better alignment with team goals and KPIs
- Fewer blockers between data and decisions
When a data mart is in place, everyday analytics feel lighter. Smaller datasets mean quicker response times, even for users running custom queries or building last-minute reports.
Because business users aren’t wading through irrelevant tables or waiting for help from data teams, they can work more independently. That autonomy speeds things up and reduces the back-and-forth that slows down cross-functional collaboration.
Data marts also help preserve the performance of your central warehouse. By offloading high-frequency, low-complexity queries to a localized layer, you free up compute power and keep broader systems running smoothly.
And since marts are structured around the way a specific team thinks (campaigns for marketing, funnel stages for sales, expense categories for finance), their insights are easier to interpret and act on.
Just make sure your governance strategy keeps pace as you scale by brushing up on the Best Practices for Data Governance.
When to Use a Data Mart?
👉 Use a data mart when a specific team needs fast, simplified access to just their piece of the puzzle.
Not Sure Where Your Data Belongs? Let’s Figure It Out
If you’re weighing data lakes against warehouses or wondering whether it’s time to introduce data marts, you’re already asking the right questions.
At HatchWorks AI, we help organizations design and evolve their data ecosystems with purpose, ensuring you have relevant data every step. Whether you’re starting from an existing warehouse, expanding into a lake, or looking to reduce redundancy across teams, we bring the strategy, tools, and hands-on support to make it work.
And if GenAI is on your roadmap, the right foundation becomes even more important.
Data Lakehouse Migration
Top Databricks Talent
AI Solution Development
Unified Data Governance
Democratized Analytics
Conversational AI on Databricks
Build a Databricks RAG (Retrieval Augmented Generation) solution to unify structured and unstructured data, enabling tailored AI-driven experiences.
Make Data Your Biggest Differentiator
We build scalable, modern data systems tailored for AI.
Using Databricks’ industry-leading platform, we ensure your data is ready, secure, and optimized for AI.



