
This guide distills our Databricks experience into actionable best practices that help you maximize performance while minimizing cost and complexity.

Understanding the Databricks Data Intelligence Platform
Before we get into best practices, let’s clarify what Databricks is and who it’s for.
The Databricks Data Intelligence Platform is a cloud-based ecosystem designed to simplify the end-to-end journey of data engineering, data science, and analytics.
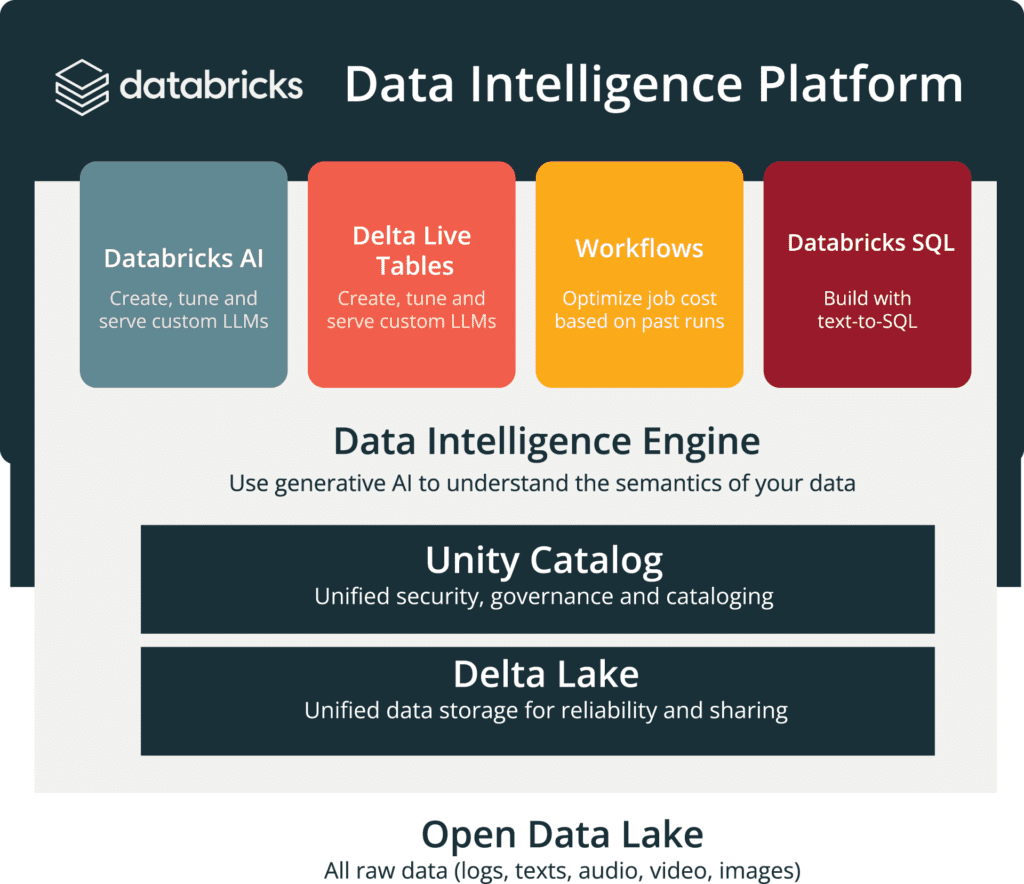
By consolidating diverse tools into a single, unified workspace, it enables teams to move seamlessly from data ingestion to advanced analytics and machine learning.

1. Setting Up Your Databricks Workspace for Success
A well-organized workspace lays the groundwork for efficient, secure, and compliant data processing.
Jump in without it and you’ll quickly find yourself battling cluttered data pipelines, security gaps, and compliance headaches that can slow down your progress and compromise the integrity of your work.
Here’s how to get set up successfully:
- Create dedicated folders for different projects, departments, or data domains. A logical folder structure keeps resources easy to find and simplifies collaboration.
- Establish naming conventions and use tags to quickly identify the purpose and stage of each notebook. Make sure they’re used across your workplace for consistency.
- Clearly define user roles and permissions to ensure that only authorized personnel can access or modify critical data and resources.
This organized approach will streamline your data management and guarantee your primary data processing environment is designed to support efficient data access, data processing, and data storage.
Then you can enable data scientists and data engineers to focus on exploratory data analysis and machine learning model development.
⚙️ Optimize your setup! Find out how Databricks MLOps can simplify your machine learning operations.
2. Getting Your Data Organized (Governance Best Practices)
With the foundation set, you can start to look at properly organizing your data assets for optimal performance and management. This requires you to play a data isolation model, organizing the data into a primary domain, and configuring external locations and storage credentials.
Plan your data isolation model
Start by planning your data isolation model. This involves defining clear boundaries between environments or different organizational units, ensuring that each group or project has its own dedicated space.
Leveraging Databricks workspaces as your primary data processing environment is a smart move, but be aware of the drawbacks that can come with shared workspaces.
Organize your data into a primary data domain
Unity Catalog is a powerful tool for structuring both metadata and data, allowing you to configure storage locations at the metastore, catalog, or schema level. This helps ensure that data is stored in designated accounts or buckets within your cloud tenant, providing better control and governance over your data assets.
Configure external locations and storage credentials
Use external locations to register landing areas for raw data produced by external systems, and restrict the creation of these locations to administrators or trusted data engineers.
External volumes can then be used to provide file storage locations that serve the needs of data scientists, data analysts, and machine learning engineers. This ensures all essential data files are securely and efficiently managed.
🛡️ Secure your data and boost your data governance with our AI Data Readiness & Governance Assessment.
3. Keeping Your Data Safe (Security Best Practices)
Your data is precious and the last thing you want to do is compromise it. So, you need a security strategy that has:
- Multi-layered protection that secures infrastructure, data, access points, and applications
- Fine-grained role-based access control (RBAC) to assign appropriate permissions at workspace, cluster, notebook, and job levels
- Robust encryption protocols for data at rest in storage and in transit across your network
Let’s look at two proven best practices you can implement to get that strategy off the ground:
Configure access control
Unity Catalog centralizes data governance, enabling you to define specific access rules for different data assets. By ensuring that production data remains isolated and accessible only to authorized users, Unity Catalog plays a crucial role in safeguarding your sensitive information.
Encryption is another vital component. It’s essential to secure data both at rest and in transit. Robust encryption protocols help protect your data against breaches, ensuring that information remains confidential and integral as it moves through various stages of processing.
Use automated workflows for jobs
Secure and automated workflows are key to maintaining a resilient data environment.
Use Databricks Jobs to orchestrate your data processing, machine learning, and analytics pipelines, reducing the need for manual intervention and thereby minimizing potential vulnerabilities.
While external orchestrators can also manage assets, notebooks, and jobs, it is recommended to rely on Databricks Jobs for all internal task dependencies to ensure consistency and security.
4. Production Environment Best Practices
Your data platform is only as good as the pipelines that power it. Here are our three best practice tips to help you set up a production environment where data pipelines are effortless to manage:
Use ETL frameworks for data pipelines
Delta Live Tables transform how teams build data pipelines in Databricks. Rather than stitching together complex workflows, you define what your transformations should accomplish and let the declarative framework handle the heavy lifting. This approach:
- Embeds data quality checks directly into your pipeline code
- Automatically generates lineage graphs showing data dependencies
- Handles task orchestration and cluster scaling without manual intervention
With expectations built into your pipeline, data issues get caught early, preventing bad data from flowing downstream and compromising business decisions.
Automate ML experiment tracking
Keeping track of ML experiments manually is tedious and error-prone. Databricks Autologging eliminates this burden by automatically capturing model parameters, performance metrics, dataset snapshots, and environment details for reproducibility.
This no-code approach ensures complete experiment history even when data scientists are focused on rapid iteration. When it’s time to move to production, the full lineage is already documented and ready to support governance requirements.
Reuse the same infrastructure to manage ML pipelines
Why maintain separate systems for data and ML workflows?
The Databricks platform allows unified management through Terraform-driven environment deployment for consistent ML infrastructure.
Your data and ML pipelines can share common components for data preparation, while enterprise-grade Model Serving provides deployment capabilities with built-in monitoring.
5. On the Lookout for Bottlenecks (Monitoring and Observability Best Practices)
Want to keep your Databricks environment working? You’ll have to monitor its performance. Of course, that doesn’t mean staring at the screen all day. It means:
- Using shared high concurrency clusters
- Supporting batch ETL workloads with single user ephemeral standard clusters
- Choosing cluster VMs to match workload classes
If that all sounds like jargon, don’t fret. We’ll explain below:
Support interactive analytics using shared high concurrency clusters
Interactive workloads are different from batch workloads in terms of cost variability and optimization for latency over throughput. When data scientists and analysts run ad-hoc queries, they expect immediate responses and smooth performance.
Supporting interactive workloads entails minimizing cost variability and optimizing for latency over throughput, while providing a secure environment. Shared high concurrency clusters excel at this by distributing resources efficiently across multiple users, ensuring everyone gets responsive performance without dedicated infrastructure.
Support batch ETL workloads with single user ephemeral standard clusters
Unlike interactive workloads, logic in batch jobs is well defined and their cluster resource requirements are known a priori. These predictable workloads don’t need the flexibility of shared resources.
To minimize cost, there’s no reason to follow the shared cluster model. We recommend letting each job create a separate cluster for its execution. These ephemeral clusters spin up when needed, complete their tasks, and shut down automatically—eliminating idle time and unnecessary expenses.
Choose cluster VMs to match workload class
One size definitely doesn’t fit all when it comes to Databricks clusters.
Machine learning workloads, for instance, typically require caching all data in memory for efficient model training. These jobs benefit from memory-optimized VM types with higher RAM-to-CPU ratios, while complex deep learning might need GPU acceleration for optimal performance.
By tailoring your infrastructure to these workload patterns, you’ll achieve both better performance and lower costs—the best of both worlds for your data platform.
6. Best Practices for Storing Your Data
Do Not Store Any Production Data in Default DBFS Folders
Every Databricks workspace comes with a default DBFS (Databricks File System), but don’t be fooled into using it as your primary data store. This space is designed for libraries, temporary files, and system-level configuration artifacts—not your valuable production data.
Using default DBFS for production data creates significant security risks. These locations don’t integrate with Unity Catalog’s governance controls and can become blind spots in your data security posture. Instead, store production data in properly governed cloud storage locations registered with Unity Catalog.
Always Hide Secrets in a Key Vault
Nothing undermines data security faster than credentials exposed in notebook code or job configurations. Hard-coded connection strings, API keys, or passwords create serious vulnerabilities that can compromise your entire environment.
Instead, leverage your cloud provider’s key vault service (Azure Key Vault, AWS Secrets Manager, etc.) integrated with Databricks secret scopes. This approach ensures credentials are encrypted, access-controlled, and never visible in plain text—even to users running the notebooks that use them.
Partition Your Data
Smart partitioning dramatically improves query performance while reducing costs. When you partition data effectively, Databricks can skip reading unnecessary files completely—known as partition pruning and data skipping.
Choose partitioning fields based on your most common query patterns. If your analysts frequently filter by date, region, or customer segment, these make excellent partition candidates. For time-series data, partitioning by year/month/day often works well, allowing queries to scan only the relevant time periods instead of the entire dataset.
That said, you want to avoid over-partitioning, which can create too many small files and actually degrade performance. The ideal partition size typically ranges from hundreds of megabytes to a few gigabytes per partition.
7. Getting Everything Live (Deployment and Maintenance Best Practices)
Strategic infrastructure decisions ensure your Databricks implementation can grow and adapt to changing needs while maintaining performance and security.
Deploy Workspaces in Multiple Subscriptions to Honor Azure Capacity Limits
Organizations naturally tend to partition Databricks workspaces by teams or departments, which creates logical boundaries for different workloads. Beyond these organizational considerations, there’s a technical dimension to this decision.
Azure subscriptions have specific capacity limits that can become constraints as your data platform grows. By distributing workspaces across multiple subscriptions, you effectively increase your overall resource ceiling and prevent any single subscription from becoming a bottleneck. This approach also provides better isolation between environments, reducing the risk that issues in one area will impact others.
Consider Isolating Each Workspace in Its Own VNet
While Databricks technically allows deploying multiple workspaces in a single Virtual Network, this approach introduces unnecessary complexity. We recommend a cleaner architecture: one workspace per VNet.
This clean separation aligns perfectly with Databricks’ workspace-level isolation model and simplifies network security management. With dedicated VNets, you can implement precise security controls for each workspace and avoid potential IP address conflicts or routing complications that might arise in shared network environments.
Select the Largest VNet CIDR
If you’re using the Bring Your Own VNet feature in Azure Databricks, the size of your VNet CIDR block directly impacts your cluster capacity potential.
The subnet masks used for your workspace enclosing VNet and the pair of subnets associated with each cluster create a mathematical ceiling on the total number of nodes you can deploy. By selecting the largest feasible VNet CIDR block, you maintain maximum flexibility for future growth.
Remember that each cluster requires two subnets (one for the driver and one for the workers), so your address space planning needs to account for this dual-subnet architecture. Generous initial allocation prevents painful network redesigns as your Databricks implementation expands.
8. Cost Optimization Best Practices for Databricks
Managing Databricks costs becomes increasingly complex as your implementation scales. While the platform delivers tremendous value, unoptimized deployments can lead to unnecessary expenses. Here’s how to keep your costs under control without sacrificing performance.
Maximize Cluster Efficiency
Autoscaling clusters can dramatically reduce costs when configured properly. For workloads with fluctuating resource demands, set appropriate minimum and maximum worker counts to allow the cluster to scale up during peak processing and down during lighter periods.
For non-critical workloads like development environments or batch jobs that can be restarted if interrupted, leverage spot instances (AWS) or low-priority VMs (Azure). These discounted resources can reduce compute costs by 70-90% compared to on-demand pricing.
Monitor your cluster usage patterns with Databricks’ built-in metrics. Identify long-running, underutilized clusters that could benefit from more aggressive auto-termination settings or job-based scheduling.
Invest in Capacity Planning
Proper capacity planning prevents both resource shortages and wasteful over-provisioning. Plan for variations in expected load by analyzing historical usage patterns and anticipated growth.
Test how your environment handles both predictable and unexpected load variations. This proactive testing helps identify potential bottlenecks before they impact production workloads.
For mission-critical applications, ensure all regions can scale sufficiently to support total load if one region fails. This redundancy provides business continuity while preventing rushed, expensive provisioning during outages.
Use Cost Management and Chargeback Analysis
Databricks provides powerful tools for understanding and optimizing costs. The Cost Estimator helps predict expenses for new workloads, while the Cost Analyzer provides visibility into actual resource utilization.
Implement a consistent tagging strategy using Azure Tags to associate resources with specific projects, departments, or initiatives. These tags enable granular reporting and analysis of costs across your organization.
Filter cost reports by tags to implement chargeback models, ensuring teams are accountable for their resource consumption. This visibility typically drives more cost-conscious behavior and identifies opportunities to optimize resource utilization.
Hands-On with the Databricks Sandbox
Watch our video walkthrough by Julian Arango, Senior AI Engineer, and see how Hatchers are using the Databricks Sandbox to learn, experiment, and innovate.
Make Data Your Biggest Differentiator
We build scalable, modern data systems tailored for AI.
Using Databricks’ industry-leading platform, we ensure your data is ready, secure, and optimized for AI.



