
AI chatbots are transforming how we interact with technology, ensuring their reliability and accuracy has never been more critical. Retrieval-Augmented Generation (RAG) systems combine the power of Large Language Models (LLMs) with real-time information retrieval to produce responses that are both contextually rich and factually grounded.
However, validating the performance, user experience, and trustworthiness of these complex AI chatbots requires a robust, multi-layered testing strategy.

👋Hi, I’m Maria Araya, SDET at HatchWorks AI, and I’m excited to share my insights on agile testing and AI integration. With over eight years of experience in software quality assurance—spanning roles at Intel Corporation, QAT Global, and Smash Costa Rica—I’ve seen firsthand how critical it is to foster innovation, collaboration, and continuous improvement in modern development environments. My passion lies in blending robust testing strategies with agile methodologies to ensure high-performing, reliable solutions that truly empower businesses to thrive in today’s competitive landscape.
In this guide, you’ll discover how RAG systems work, why specialized testing is indispensable, and which metrics best capture both retrieval accuracy and generation quality. We’ll delve into best practices for unit testing, integration testing, and end-to-end evaluations—highlighting common pitfalls along the way.
Whether you’re developing a new RAG-powered AI chatbot or refining an existing one, this article offers actionable insights to help you build dependable, high-performing conversational agents that truly meet user needs.
1. Introduction
1.1 What is a RAG system?
Retrieval-Augmented Generation (RAG) AI is an emerging pattern used to develop AI chatbots capable of producing more comprehensive and accurate responses than is possible using Large Language Models (LLMs) alone. RAG systems combine the retrieval of relevant information from external sources with the ability to generate human-like text.
This approach results in responses that are not only relevant but also grounded in factual data, thereby enhancing user trust and satisfaction. A comprehensive testing strategy is crucial to guarantee the quality, reliability, and user satisfaction of RAG systems, as these systems are often complex and require rigorous validation at various stages of development.This article outlines a multi-faceted testing strategy for a chatbot that utilizes RAG.
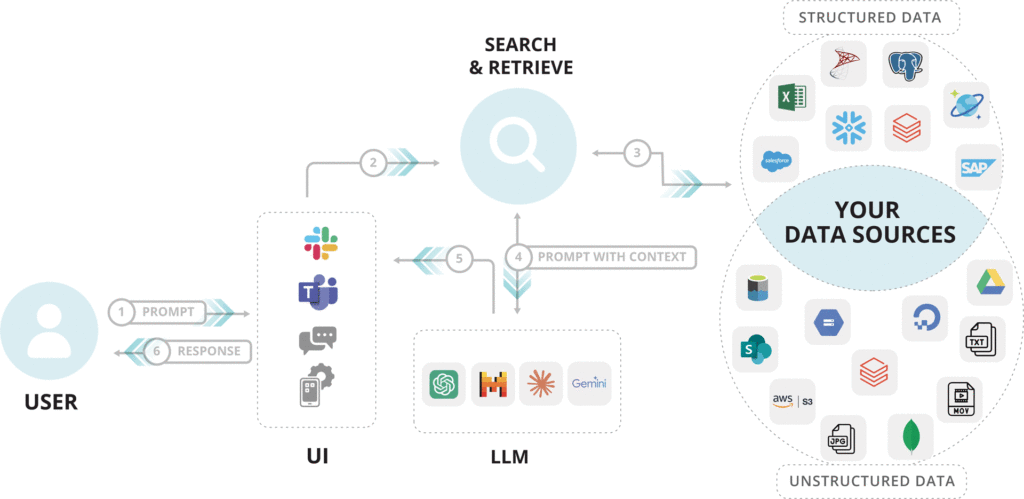
Understanding RAG architecture
Retrieval-Augmented Generation (RAG) systems bring up-to-date proprietary information to your generative models to produce responses grounded in the searched data. The architecture integrates two main components:
- Retriever: It extracts relevant documents from a corpus.The retriever is responsible for identifying and extracting relevant documents from a knowledge base or a corpus of data in response to a user query.
- Generator: The generator component then processes the retrieved documents, leveraging powerful language models like T5 or GPT to generate coherent and contextually appropriate responses
These models excel at understanding natural language and constructing human-like text, making them ideal for crafting chatbot responses. The seamless interaction between these two components is facilitated by an integration layer that ensures smooth data flow and communication.
1.2 Importance of Testing RAG systems
Testing plays a crucial role in ensuring the accurate retrieval of information, maintaining consistent performance across diverse queries, and identifying potential biases, inaccuracies, and inconsistencies.
By rigorously evaluating the system under varied scenarios, testing helps uncover and address issues that could affect reliability and fairness, thereby enhancing the overall quality and robustness of the solution. This process is essential for building trust in systems that rely on accurate data processing and user interaction.
1.3 Understanding RAG systems
Components of RAG systems
The retriever implements algorithms such as BM25 or dense retrieval models like Dense Passage Retrieval (DPR). While the generator leverages large language models (e.g., T5, GPT). It’s common to integrate an integration layer, which facilitates seamless interaction between retriever and generator components.
Common use cases and applications include Question Answering (QA) systems, which deliver accurate responses to user queries by leveraging extensive knowledge bases, and summarization tools that create concise summaries of lengthy texts, highlighting key information.
Personalized AI chatbots are another vital application, offering tailored and contextually relevant responses to meet specific user needs. Additionally, knowledge management systems play a significant role in organizing and retrieving information within organizations, enhancing knowledge sharing and discovery. These applications collectively demonstrate the versatility and impact of advanced AI technologies.
1.4 Challenges in Testing RAG systems
The integration of retriever and generator components in Retrieval-Augmented Generation (RAG) systems presents unique challenges that demand a robust testing framework. The complexity of integration because the interconnected nature of these components requires thorough end-to-end validation to ensure seamless interaction and effective handling of diverse data scenarios.
Variability in retrieval results, such as incomplete, ambiguous, or contradictory information, directly impacts the generator’s output, necessitating testing strategies that account for these complexities. Additionally, evaluating the generated content for factual correctness, relevance, and coherence is intricate, as automated metrics often fall short in capturing the nuances of human language and understanding.
Addressing these challenges is essential to build reliable, high-performing RAG systems capable of delivering accurate and contextually relevant responses.
2. Testing methodologies – A multi-layered testing approach
The testing strategy for this project uses a multi-layered approach that encompasses various testing methodologies to address the inherent complexities of RAG. This approach ensures that the chatbot is thoroughly validated at different levels of development and deployment.
2.1 Unit Testing
- The retrieval component focuses on validating the accuracy and completeness of the information retrieved, ensuring that relevant documents are effectively identified and extracted from the data corpus in response to diverse user queries. Key metrics such as Precision and Recall are utilized to evaluate retrieval performance, measuring both the accuracy and comprehensiveness of the results. Additionally, this component addresses the challenge of handling ambiguous queries by simulating user inputs that are vague or open to multiple interpretations, assessing the retriever’s resilience and ability to deliver relevant results under such conditions.
- The generation component emphasizes evaluating the quality and coherence of the responses produced. Using a set of retrieved documents, the generator is tasked with processing the information to deliver responses that are factually accurate and contextually relevant to the user’s query. Key aspects include assessing linguistic coherence, which involves fluency and grammatical correctness, and semantic relevance, which ensures that the generated text aligns meaningfully with the user’s intent and the provided context.
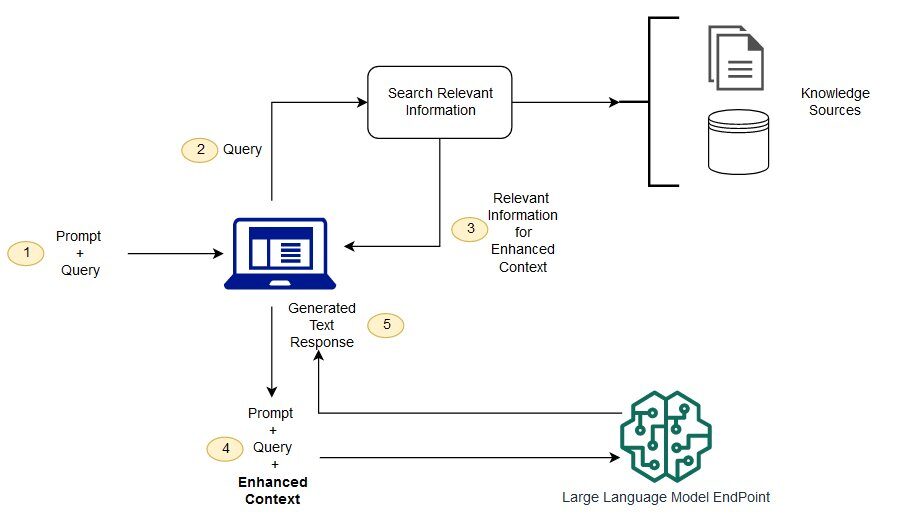
2.2 Integration Testing
This level of testing ensures that the retriever and generator components work together seamlessly. Test cases should simulate various scenarios, including cases where the retrieved information might be incomplete, ambiguous, or even conflicting. The integration layer, responsible for facilitating the interaction between these two components, should be rigorously tested to ensure smooth data flow and communication.- Mocking frameworks: Employ mock frameworks to simulate the interaction between the retriever and generator. This allows testers to isolate and test specific functionalities and data flows within the system.
- Data pipeline validation: Verify the integrity of the data pipeline, ensuring that data is correctly transferred and transformed between different system components.
To guarantee that the different components of the RAG system work together seamlessly, the team employed mock frameworks to simulate the interactions between the retriever and the generator. This step was critical to validate the data pipeline, ensuring that data is correctly transferred and processed between the components. The team also focused on verifying the appropriate management of dependencies between the components to avoid conflicts or errors during execution.
2.3 End-to-End Testing
The system or end-to-end tests evaluate the system’s functionality as a whole, examining the entire process from the user inputting a query to the chatbot generating a response. It simulates real-world user interactions to assess the system’s overall performance, including accuracy, response time, and user experience.
Normally, this testing helps to uncover any potential issues that might arise from the interaction of different components, which might not be apparent during unit or integration testing. In the case of a RAG chatbot the consolidation a set or well covered questions including cases for error handling cases, and context cases. The implementation of an AI agent for this purpose is something useful to be integrated.
2.4 Confusion Matrix: A powerful tool for performance evaluation
The integration of a confusion matrix to measure the chatbot’s ability to provide accurate and relevant responses was implemented. The confusion matrix categorizes the chatbot’s responses into four distinct categories:
- True Positives (TP): These represent instances where the chatbot successfully retrieved the correct information and formulated a relevant and accurate response .For example, if the chatbot was asked about the company’s holiday schedule and provided the correct list of holidays, it would be categorized as a TP.
- False Positives (FP): FPs occur when the chatbot generates a response that is either irrelevant to the query or factually incorrect.For instance, if the chatbot provided information about vacation policies when asked about sick leave, this would be an FP.
- False Negatives (FN): FNs represent situations where the chatbot fails to provide a relevant response despite having access to the necessary information. This could happen if the chatbot was unable to understand the user’s query or if the retriever failed to identify the relevant documents.
- True Negatives (TN): TNs occur when the chatbot correctly chooses not to generate a response because there is no relevant information available to address the user’s query. For example, if the chatbot was asked about salary information, which is confidential, and refused to provide an answer, this would be classified as a TN.

By analyzing the confusion matrix, testers can identify patterns of errors and gain insights into the strengths and weaknesses of the RAG system. This information is crucial for improving the accuracy and reliability of the system.
2.5 Automating large-scale testing with an agent and embeddings
Once a set of questions are ready and defined to test the chatbot, the test execution involves classifying each answer according to the confusion matrix categories. However, this process can be time consuming if we are covering different languages.
To conduct large-scale testing efficiently, develop an agent to automate the process of interacting with the chatbot. This agent was responsible for sending a series of pre-defined questions to the chatbot using an API, capturing its responses, and preparing the data for further analysis. This pattern of using an agent to test another agent is known as Agent as Judge and is a cornerstone of LLM development.
The semantic analysis of the chatbot’s responses is done by the same AI retrieval model used in the RAG. A prompt is done to classify each response in one of the expected four classifications and using a basic expected response or keywords. By mapping the chatbot’s responses into this vector space, it’s possible to evaluate their similarity based on their semantic meaning rather than relying solely on keyword matching.
This approach allowed for a more nuanced and accurate assessment of the chatbot’s responses. After comparing the responses using embeddings, the agent categorized them into the four categories defined in the confusion matrix, allowing for the automated calculation of the performance metrics of the AI models as a whole.
3. Evaluation metrics
3.1 Measuring retrieval performance
These metrics, derived from the confusion matrix, provide a quantitative assessment of the system’s performance. The confusion matrix data was used to calculate important performance metrics like Accuracy, Precision, Recall, and F1-score.These metrics allow objectively quantifying the chatbot’s ability to provide correct and relevant information.- Accuracy: Accuracy measures the overall correctness of the chatbot’s responses by calculating the ratio of correct responses (TP + TN) to the total number of responses generated. This metric provides a general overview of the chatbot’s performance.
- Precision: Precision focuses on the proportion of responses that are truly relevant to the user’s query. It is calculated as TP / (TP + FP). This metric is particularly useful for assessing the chatbot’s ability to avoid providing irrelevant or incorrect information.
- Recall (Exhaustivity): Recall assesses the chatbot’s ability to retrieve and provide all the relevant answers for a given query. It is calculated as TP / (TP + FN). This metric is crucial for ensuring that the chatbot doesn’t miss any important information.
- F1-Score: The F1-score offers a balanced view of both Precision and Recall by calculating their harmonic mean. This metric is particularly helpful when both precision and recall are considered equally important.
By closely monitoring these metrics, the team was able to track the chatbot’s performance over time, identify areas for improvement, and make data-driven decisions regarding the development process.
3.2 Assessing generation quality
In addition to these core metrics, the sources suggest other measures for evaluating RAG systems:
- BLEU (Bilingual Evaluation Understudy): Useful for assessing the fluency and grammatical correctness of generated text, often used in machine translation tasks. Measures the n-gram overlap between generated text and reference texts, useful for evaluating fluency and grammatical correctness.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Suitable for evaluating the content overlap between the generated text and a set of reference summaries, often employed in text summarization tasks. Evaluates recall-oriented metrics by assessing the overlap of sequences between generated text and reference summaries, often used in text summarization.
- METEOR (Metric for Evaluation of Translation with Explicit ORdering): Takes into account synonyms and paraphrases, providing a more nuanced evaluation of semantic similarity between the generated text and reference texts. Accounts for synonymy and semantic similarity.Considers synonyms and paraphrases to evaluate semantic similarity between generated and reference texts, offering a more nuanced assessment.
3.3 Human evaluation techniques
Human evaluation remains an essential aspect of testing RAG systems, especially in applications where subjective aspects like coherence, fluency, and relevance are crucial. Expert reviews, incorporating human judgment, are essential for evaluating subjective aspects like coherence, fluency, and relevance of the generated content, which automatic metrics might not fully capture.
3.4 User experience metrics
Evaluating the user experience is paramount for RAG systems intended for real-world use. Key metrics include:
- Response time: The speed at which the system provides responses, which is critical for maintaining user engagement. Measure response time for critical queries.
- User satisfaction: Measured through surveys or other feedback mechanisms, providing insights into the overall user experience and areas for improvement. Collect user satisfaction scores via surveys.
4. Tools and frameworks for testing
4.1 Automated testing tools
LangChain, Pytest, and other frameworks like TensorFlow, PyTorch, and HuggingFace are useful to streamline automated evaluations for both retrieval and generation components.
4.2 Simulation and mocking frameworks
Simulated retrieval results for isolating and testing the generator independently.
4.3 Data Annotation and Validation Tools
Tools such as Label Studio aid in consistent data labeling and validation.
5. Best practices in testing RAG systems
5.1 Data Quality Assurance
Using clean and unbiased datasets is essential to ensure the reliability of trained models and test results by eliminating errors, inconsistencies, and biases that could compromise performance. Additionally, incorporating diverse datasets that encompass a broad range of scenarios and data distributions enhances the system’s robustness, enabling it to handle unexpected inputs effectively and maintain consistent performance across varied contexts.
5.2 Continuous integration and deployment (CI/CD)
The automation of the testing pipelines to accommodate frequent model updates and streamline the integration of new features or improvements. This practice ensures continuous quality assurance in different levels if the system handles different levels of automated tests like the unit, integration and system testing.
5.3 Logging and monitoring
Implement real-time monitoring of key performance indicators (KPIs) in production environments. This enables tracking system performance, identifying potential issues early on, and facilitating proactive maintenance.
5.4 Security and privacy considerations
Encrypt sensitive data and ensure compliance with relevant data privacy regulations like GDPR. Security testing should be integrated into the testing process to safeguard user data and system integrity.
5.5 Leveraging agile principles for iterative development and testing
The development and testing process for this chatbot embraced Agile principles, prioritizing flexibility, collaboration, and iterative development.
Rather than adopting a sequential approach where testing occurs only after development is completed, the team integrated testing activities throughout the entire development process. This included incorporating unit testing, integration testing, security testing, and performance testing iteratively within each development sprint.
This iterative approach brought significant benefits:
- Continuous feedback: By continuously testing the chatbot, the team was able to gather valuable feedback on its performance and functionality throughout the development process.
- Early issue detection: The iterative nature of Agile allowed the team to identify and address issues early in the development cycle, preventing the accumulation of technical debt and reducing the cost of fixing problems later.
- Enhanced collaboration: Integrating testing within the development sprints fostered collaboration between developers, testers, and other stakeholders, encouraging open communication and a shared understanding of the project goals.
- Continuous improvement: The continuous feedback loop inherent in Agile methodology facilitated the chatbot’s evolution throughout the development process. By addressing issues and implementing improvements iteratively, the team ensured that the final product was highly refined and met the required quality standards.

Want to harness GenAI without risking inaccuracies and data leaks?
Get expert tips on grounding your AI in relevant, real-time enterprise data.
This free e-book reveals how to reduce costs, ensure security, and create personalized AI experiences—making your proprietary data a true differentiator.
6. Common Pitfalls and How to Avoid Them
6.1 Handling Ambiguous Queries
Robust fallback mechanisms are essential for managing uncertain or ambiguous user inputs, enabling the system to prompt users for clarification or provide a range of potential interpretations.
Additionally, integrating advanced natural language processing (NLP) techniques enhances the system’s ability to detect and address ambiguities in user queries, improving its overall understanding of user intent and ensuring more accurate and contextually relevant responses.
6.2 Dealing with out-of-distribution data
Regular model retraining is crucial to ensure that models remain adaptable to evolving data distributions, maintaining optimal performance as new trends or information emerge.
Additionally, domain adaptation techniques allow models to adjust to data from various domains or contexts, enhancing their ability to generalize and ensuring resilience to unfamiliar or unexpected inputs.
6.3 Mitigating bias and ethical concerns
Fairness-aware metrics should be employed to assess and mitigate potential biases in both the retrieval and generation processes, ensuring that the system treats all users and data equitably.
Additionally, an ethical review framework is essential to evaluate the societal impacts of the RAG system, promoting responsible development and deployment practices that prioritize ethical considerations and the well-being of users and communities.
7. Future Directions
7.1 Advances in Testing Methodologies
- Adversarial Testing: Incorporate adversarial testing techniques to evaluate the system’s robustness against malicious attacks and identify vulnerabilities.
- Interpretable AI Tools: Integrate tools that offer insights into the system’s decision-making process, making it easier to understand why the system generates specific outputs.
7.2 Emerging Challenges
- Multi-modal RAG systems: Address the testing complexities of RAG systems that handle both textual and visual input, requiring specialized testing methodologies to evaluate multi-modal understanding.
- Dynamic data environments: Develop strategies to handle constantly changing data environments and ensure that models remain up-to-date and adapt to new information effectively.
7.3 Role of AI in Automated Testing
- Edge-Case generation: Utilize AI to automatically generate test cases that cover edge cases and unusual scenarios, expanding test coverage and uncovering potential vulnerabilities.
- Dynamic scenario simulation: Leverage AI for creating dynamic test scenarios that mimic real-world user interactions, leading to more realistic and comprehensive system evaluations.

Tailor-Made AI With Your Proprietary Data
Tired of AI models that lack context from your private data?
See how Retrieval-Augmented Generation (RAG) helps you securely integrate both structured and unstructured data into any LLM—boosting accuracy, preventing hallucinations, and reducing training costs.
8. Conclusion
Developing and testing a high-performing chatbot with RAG demands a thorough approach that addresses the system’s inherent complexities and the nuances of evaluating generated language. By adopting a multi-layered testing strategy that incorporates unit testing, integration testing, end-to-end testing, and the utilization of a confusion matrix for performance evaluation, the team was able to comprehensively validate the chatbot’s accuracy and reliability.
Furthermore, automating the testing process using an agent and employing embeddings for semantic comparison significantly improved the efficiency and effectiveness of the testing process. Finally, embracing Agile principles fostered a collaborative and iterative development cycle, allowing the team to continuously adapt to changing requirements and ensure the delivery of a high-quality product.
8.1 Recap of Key Points
Testing RAG systems demands a specialized framework designed to address the unique challenges of these AI-driven systems. Evaluation combines automated metrics such as Precision, Recall, F1-Score, BLEU, ROUGE, and METEOR, alongside human assessments, to capture both the objective and subjective dimensions of system performance.
Best practices include ensuring data quality, implementing continuous integration and deployment, maintaining comprehensive logging and monitoring, and prioritizing security and privacy to safeguard sensitive information while ensuring reliable and high-quality outputs.
8.2 Final Recommendations
Explainability and transparency are critical in building RAG systems, enabling users to understand how the system generates specific responses and fostering trust in its outputs.
Equally important is bias mitigation and fairness, ensuring that all aspects of the system—from data selection to model training and response generation—promote equitable and unbiased outcomes.
A performance-driven approach further enhances the system by emphasizing regular evaluation, fine-tuning, and leveraging metrics and user feedback for optimization. Agile collaboration between testers, developers, and domain experts is essential to facilitate clear communication, swift issue resolution, and continuous improvement, ensuring the system meets user needs effectively.
9. Appendices
Some additional resources relevant to RAG systems and their testing are
- ISTQB CT-AI Syllabus v1.0. International Software Testing Qualifications Board.
- Karpukhin, V., Oguz, B., Min, S., et al. (2020). Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Lewis, P., Perez, E., Piktus, A., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems (NeurIPS).
- Papineni, K., Roukos, S., Ward, T., Zhu, W. J. (2002). BLEU: A Method for Automatic Evaluation of Machine Translation. Proceedings of ACL.
Turn Your Data Into a Differentiator
Access the power of AI in your enterprise with our RAG Accelerator.



